Method For 100% Reported Coverage
Originally
ADR--0128-Method for 100% Reported Coverage (v24) · Source on Confluence ↗Title
| Traceability Links | |
|---|---|
| Jama Requirements | UERQ-HLR-1090 |
| Jira Tasks |
Context
Under the [Enhanced DO-178D](confluence-title://UE/Verification Strategy) regime, under which we put our software, demands that [Test Coverage of Code Structure is Achieved](confluence-title://UE/Verification Strategy). It does so as a primary defence against unintended functionality:
“The Executable Object Code satisfies the software requirements (that is, intended function), and provides confidence in the absence of unintended functionality.“
We are also formalizing our stance on code coverage ambitions into the UERQ-HLR-1090 requirement:
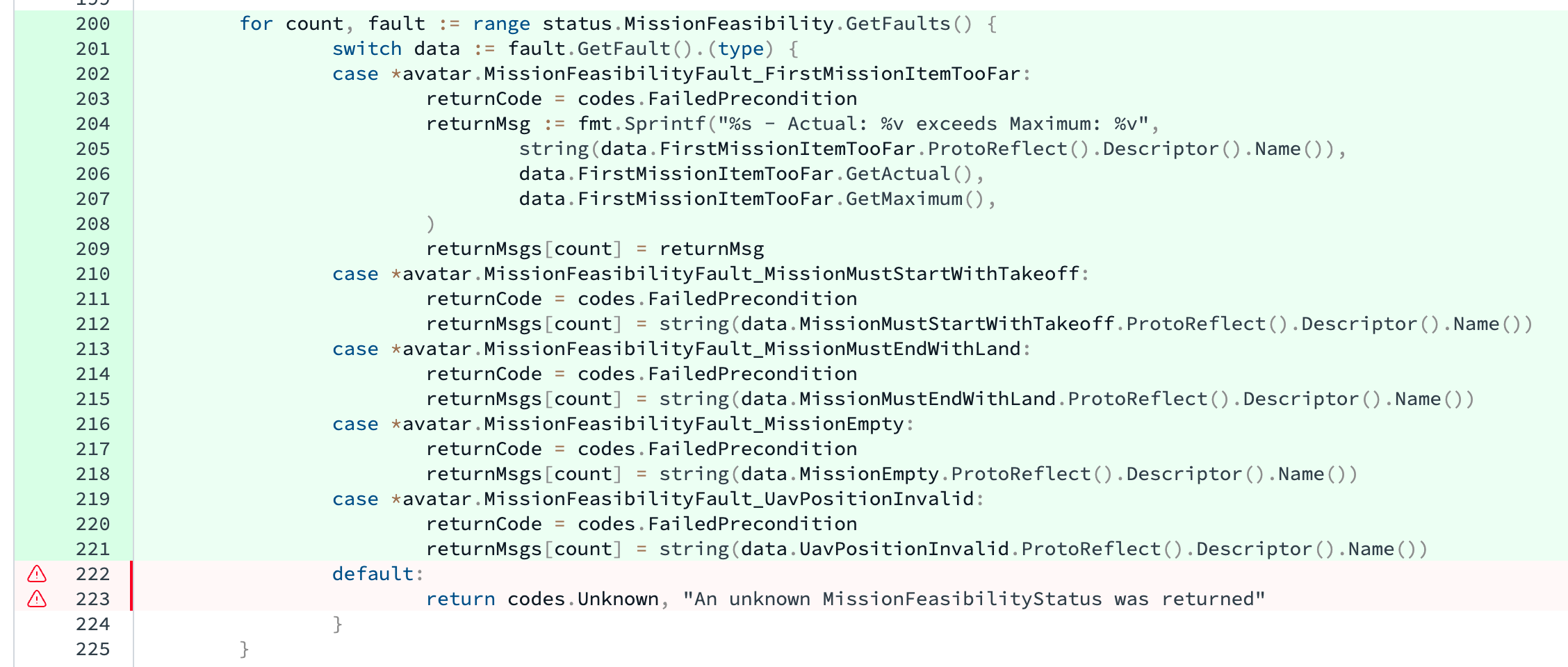
Unit and integration tests shall achieve 100% reported branch test coverage by covering the code wherever possible and where not, by annotating the uncovered code-block so that the coverage tool ignores it.
It is broadly agreed that achieving 100% code coverage is practically impossible and here are some examples to support this claim:
Defensive code anticipates future additions of fault types to production API where we can’t add test fixtures:
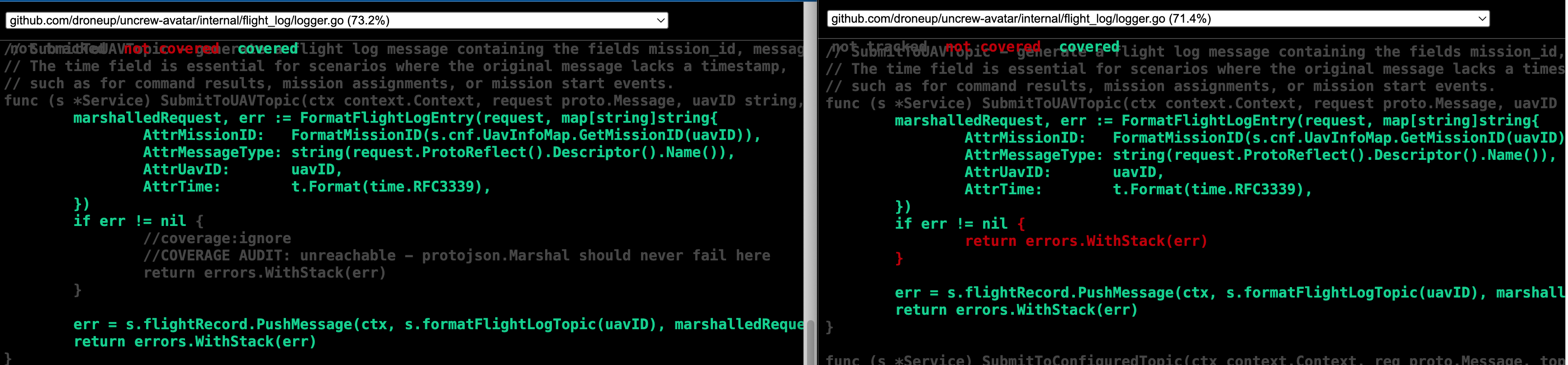
json.Marshalwill fail if given anilor something that isn’t even a structure, but our code does nothing of the sort sojson.Marshalcan never fail:
As per the standard, the behavior of
std::basic_string::operator[](size_type pos)is undefined if!(pos < size())and the function signature lacksnoexcept, allowing implementations to throw on contract violations. This is why lines 109 and 110 don’t have all their branches covered. Except in lines 98 and 104 our production software defends itself from contract violations and thus makes it impossible simulate them on lines 109 and 110.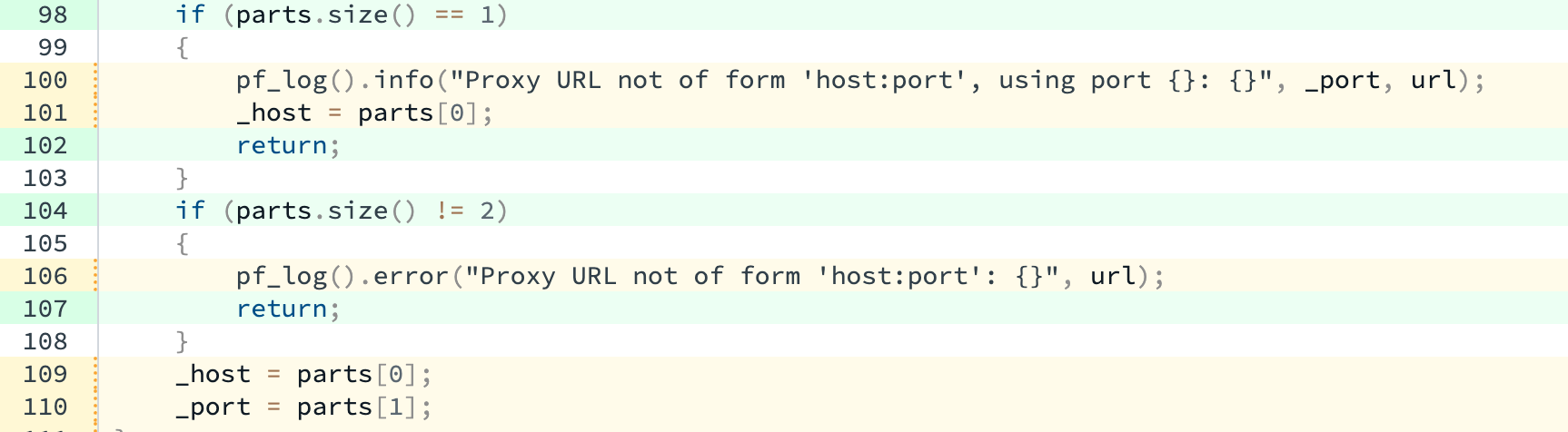
While 100% coverage appears indeed impossible, exceptions are sparse and individually justifiable.
This ADR offers a method for aiming at 100% reported branch coverage.
Codebases
C++
Some of our codebase is C++, which of course differs from golang. The differences relevant for code coverage are:
While a golang function running out of heap will crash the process, a C++ function will throw std::bad_alloc letting the caller recover. This means that every C++ function that tries to allocate memory has an additional branch that needs (or needs not) to be covered. Doing this is difficult and is referred to as OOM-testing. It involves re-running the entire test suite and letting (simulating) each consecutive memory allocation fail until all have been exercised. Executing an OOM test will rarely fit in a day, while meaningfully recovering from a OOM condition is rarely possible. Of course a C++ program can be instrumented with an allocator that crashes it on OOM conditions, but the uncovered branches will remain in the coverage report.
Error handling in golang is done with functions returning errors and forcing callers (at compile time) into handling them somehow. Meanwhile a C++ function that needs to flag an error should throw an exception. Exceptions are attractive partially because the function caller doesn’t have to handle them and if they don’t, then the exception propagates up the stack until someone does (if no one does, the program terminates). When a golang function wants to return an error, it needs to state it in its signature thus advertising an explicit branch. When a C++ function wants to throw an exception it needs to not state
noexceptin its signature. The practice is thatnoexceptis rarely used. Consider STL’sstd::map<T>::find, which doesn’t statenoexcepteven though it’s hard to imagine when it might throw. Turns out thatstd::mapcan take a user-supplied comparator which can implausibly look like so:struct BadComparator { bool operator()(const int& a, const int& b) const { if (a == 42) throw std::runtime_error("Don't like 42!"); return a < b; } };The consequence of this is that most C++ functions appear as if they might throw and that is reflected in the coverage report.
Decision
We will aim at 100% reported branch coverage by covering our code wherever possible and where not, we will annotate the uncovered code-block so that the coverage tool ignores it.
The annotation shall offer a detailed justification of the omission with links that justify whatever claims made. The annotation shall be subject to review along with the code (PR review), allowing the reviewer scrutinize the claim and only approve it only if they too don’t see a practical way to cover the annotated block.
The annotation shall always include COVERAGE AUDIT to allow grepping, and look like so:
//coverage:ignore
//COVERAGE AUDIT: unreachable - protojson.Marshal can only fail if req is nil
// https://github.com/golang/go/blob/7ecb1f36acab7b48d77991d58d456a34074a2d0e/src/encoding/json/encode.go#L68
// Here it never will be.Golang
- Use go-ignore-cov to ignore un-coverable blocks of code.
- Filter entire files out by dropping them from the coverage report.
remek.zajac@DU-LRC4MLHW7P uncrew-avatar [coverage *]$ git diff
- gotestsum -- -tags=integration ./... -coverpkg $$(go list || go list -m | head -1)/... -coverprofile $(COVERAGE_DIR)/profile.txt
+ gotestsum -- -tags=integration ./... -coverpkg $$(go list || go list -m | head -1)/... -coverprofile $(COVERAGE_DIR)/profile_full.txt
+ cat $(COVERAGE_DIR)/profile_full.txt | grep -v "_moq.go" > $(COVERAGE_DIR)/profile.txt
+ go-ignore-cov --file $(COVERAGE_DIR)/profile.txt
$(eval COVERAGE := `go tool cover -func="${COVERAGE_DIR}/profile.txt" | tail -1 | grep -Eo '[0-9]+\.[0-9]'`)Producing:
C++
GCOV-exclusion markers shall be used to ignore lines or blocks of C++ code.
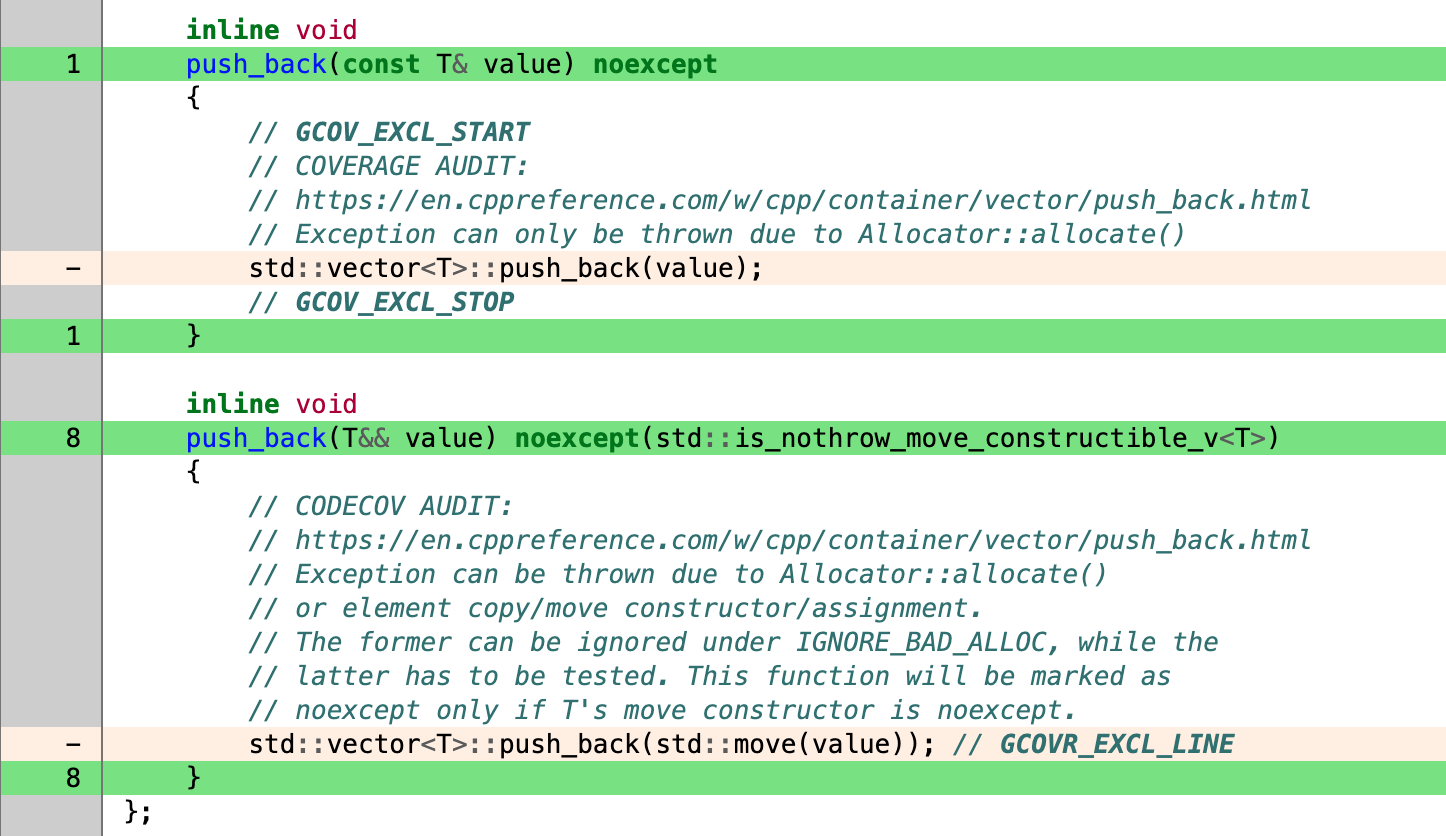
Additionally we shall ignore bad_alloc for the purpose of calculating reported code coverage. In each instance (program/executable), we will do it for either of the following reasons:
- We will instrument the program to terminate when out of memory and thus
bad_allocwill never be thrown or need to be handled. bad_alloccan be thrown, but the program’s resilience to out-of-memory conditions is (to be) tested in a dedicated OOM test cycle and sobad_alloccan be ignored when collecting test coverage reports.
Ignoring bad_alloc isn’t easy, but is practically possible as shown in the screenshot above.
JS
We use Vite’s V8 for measuring code coverage in our web projects and it offers these ways of excluding code, e.g.:
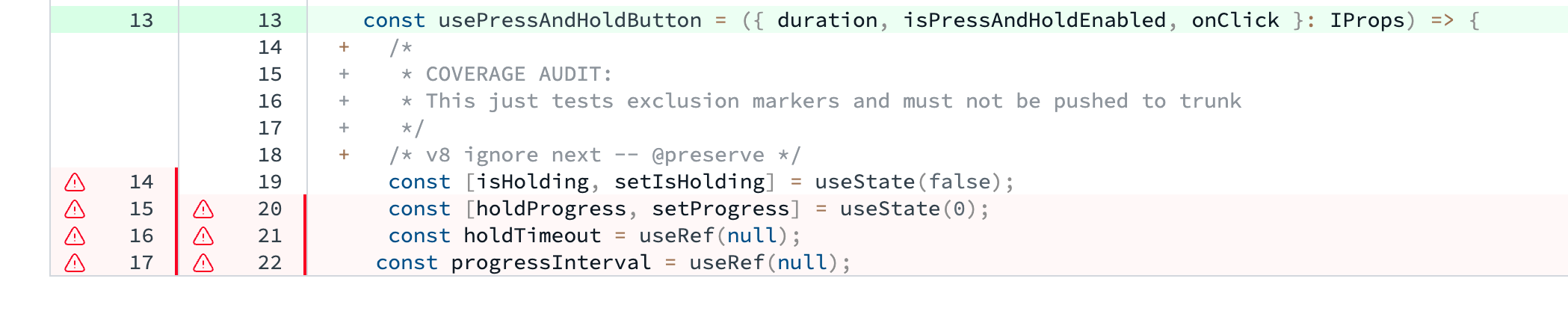
Python
Python, with which our data processing is written, is equally simple as JS. We use pytest-cov for producing code coverage reports and
# pragma: no cover
Can be used to ignore a code block from coverage analysis.
Consequences
If this document offers a shortcut towards achieving 100% test coverage, it’s probably just the last 2-3 percent-points of would otherwise be impossible to bridge. The rest can only be achieved with normal engineering effort and a lot of it. This documents offers means of accounting for lines and branches impossible or (in some exceptional cases) impractical to cover.
Put another way: we either have to accept sub-100% numbers with unknown exceptions, or we can formalize how we handle exceptions, put them through the approval process and hide them from the overall report. That way we formalize the difference between actual and reported code coverage. If we see 100% coverage, we know every exception has been approved by our process.
Alternatives Considered
GCOVR Heuristics
GCOVR is the tool we use to produce coverage reports from raw coverage execution logs (.gcno and .gcda). The community using it is well aware of the exception-handling false negatives and conclude:
Despite these approaches, 100% branch coverage will be impossible for most programs.
The approaches suggested are:
--exclude-unreachable-branchestogether with--exclude-throw-branches. The former ignores lines that seemingly contain no code, the latter ignores branches marked as exception-only. Putting aside the fact that we ought to cover some actual error handling, the flags work ingcc, but notllvm(we use the former in pathfinder and the latter in mavlink-shim). So we could coverage-test gcc compiled code in all cases, unfortunately gcc is buggy when it comes to instrumenting coverage for co-routines that we use so much around in mavlink-shim.- use decisions instead of branches - this has been promising as it generated an additional type of coverage with way better numbers that branch coverage, but it has serious flaws and Codecov that we use for storing the reports cannot be fooled to think decisions are branches.
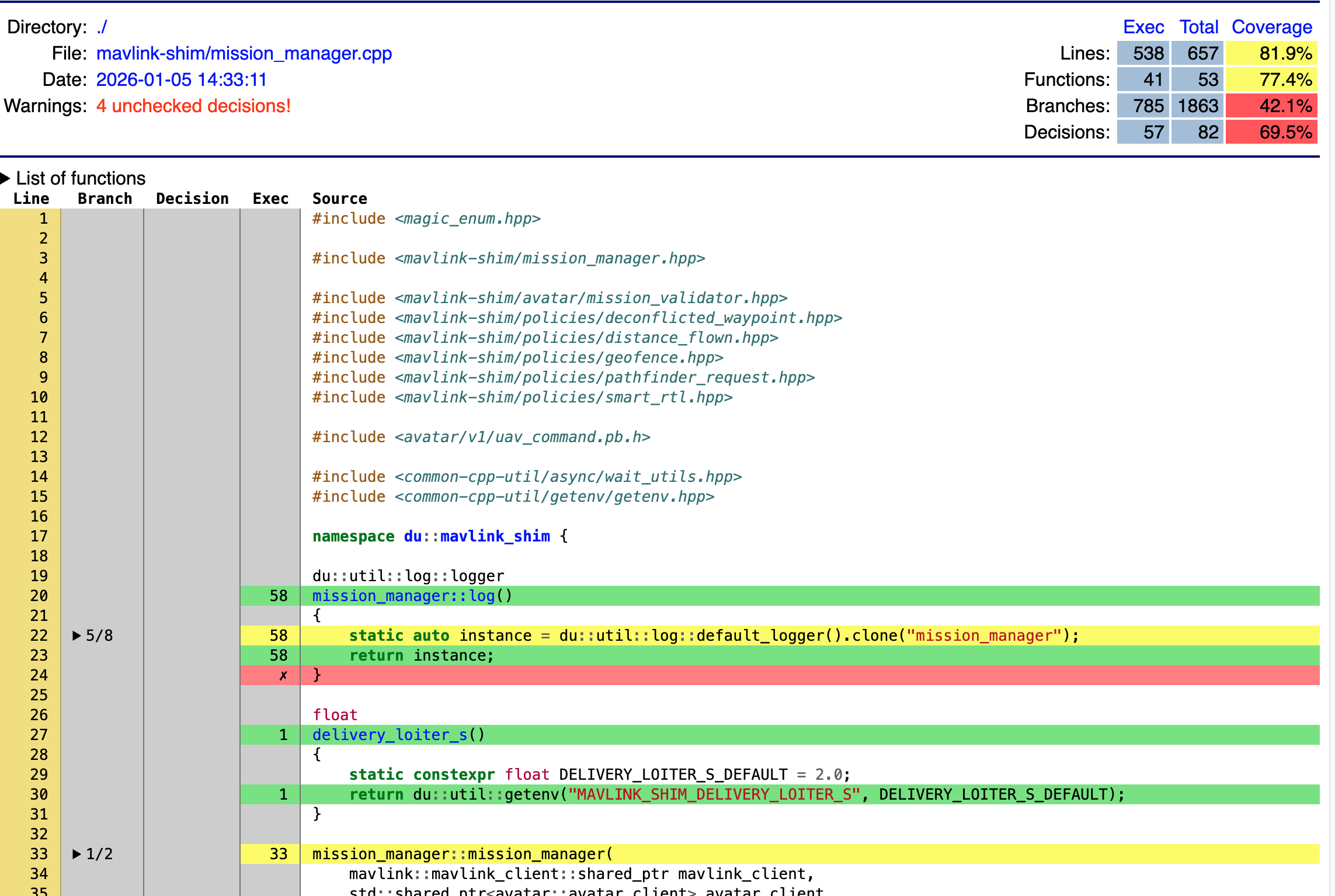
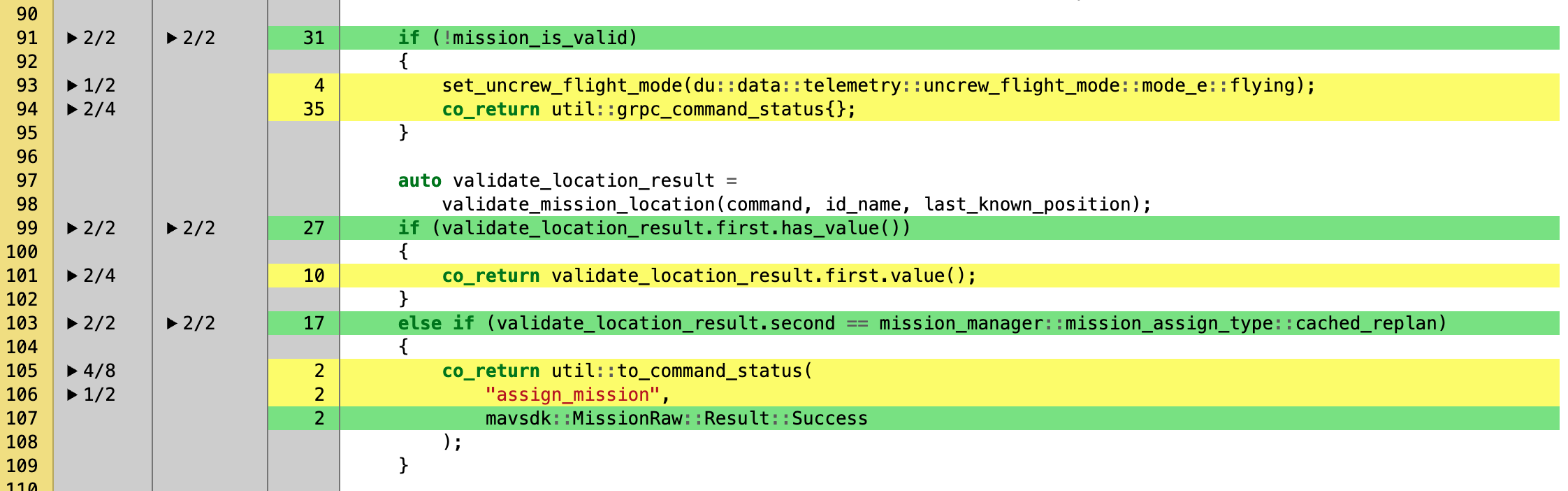
LCOV
Lcov has been tried as an alternative to Gcovr - both being coverage reporting tools. We use Gcovr so that we can covert Gcov (not Gcovr) -generated coverage execution logs (.gcno and .gcda) to a Cobertura compatible xml format that Codecov likes. Codecov is also allegedly (we never tried) content with gcov and lcov text reports. Importantly, we chose Codecov as the reporting tool and Gcovr as a format conversion tool. Perhaps we can drop gcovr one day altogether, but that’s an argument against Lcov. Lcov produces more detailed reports, can’t convert to Cobertura and doesn’t offer switches similar to --exclude-unreachable-branches together with --exclude-throw-branches . We conclude, LCov offers no advantages.
Formal Impact
Following the method described in this document and arriving at 100% coverage throughout will naturally entail a lot of effort. The method offers no shortcuts to closing the 100% coverage gap.