Airdex Ingestion Draft
Originally
ADR--0134-AIRDEX-Ingestion-Draft (v11) · Source on Confluence ↗Title
| Traceability Links | |
|---|---|
| Jama Requirements | https://droneup.jamacloud.com/perspective.req#/items/1132559?projectId=87 |
| Jira Tasks | CORE-2511 |
Context
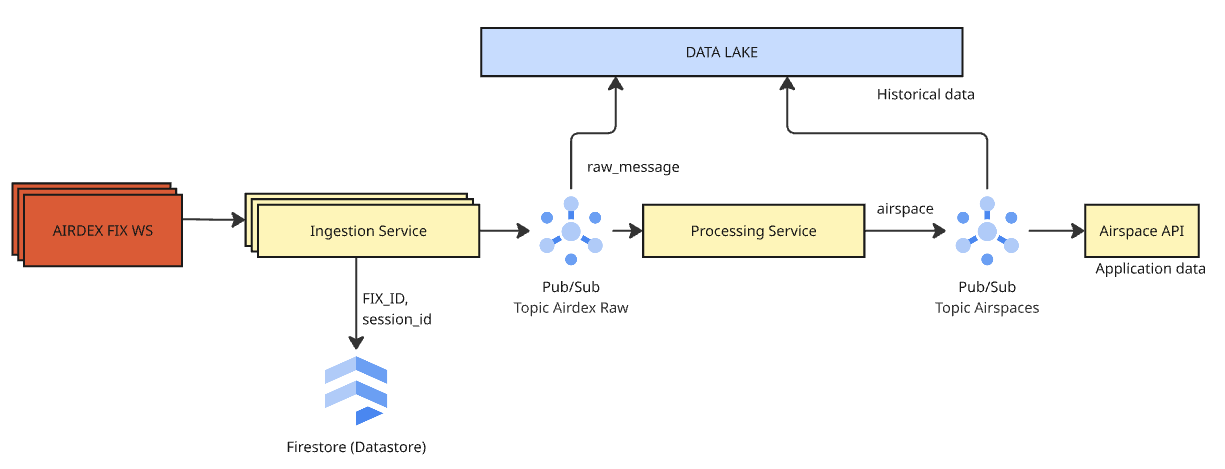
We need to design a real-time data pipeline to replicate specific advisory data from the AirDEX system into Uncrew internal ecosystem.
Datasource
The source is the AirDEX “Live Events API” (WebSocket). Each AirDEX FIX exposes its own dedicated WebSocket endpoint. AirDEX implements a custom WebSocket protocol that supports two delivery modes:
- Best-effort delivery - With this option, there is no guarantee for delivery. Messages will be received at most 1 time to a client.
- Guaranteed at-least-once delivery - Messages will be received at least once. There is a possibility that messages will be received multiple times upon a websocket reconnect. In this mode websocket expects acknowledgements for each message sent.
The API publish advisory data through a stream of events, each containing a type of change (create/update/delete)
Constraints:
- Zero Data Loss: The pipeline must guarantee at-least-once delivery. Missing an advisory update is not acceptable.
- Low Latency: Updates must be processed in real-time.
- Consistency: The internal state must remain consistent with the external AirDEX source.
Expected Failure Modes:
- Connection Instability: Websocket connections are long-lived and prone to intermittent drops, timeouts, or silent failures. The system must handle automatic reconnections and backoff strategies robustly.
- Service Interruption: Code changes, deployments, or crashes will interrupt data consumption. The system must be able to “catch up” on missed events that occurred during downtime to ensure zero data loss.
- Re-stream / Reconciliation: Downstream consumers may require a full dump of the current state. The system should support on-demand re-streaming or periodic reconciliation.
Performance requirements:
- We process one message at time per fix
- Once message reaches Ingestion Service ist must be processed and propagated through uncrew backend in less than 5 seconds
- We expect that Airspace Pub/Sub have one consumer only - Airspace API
- We expect that traffic generated by Airdex is less than 1000 messages/min
Decision
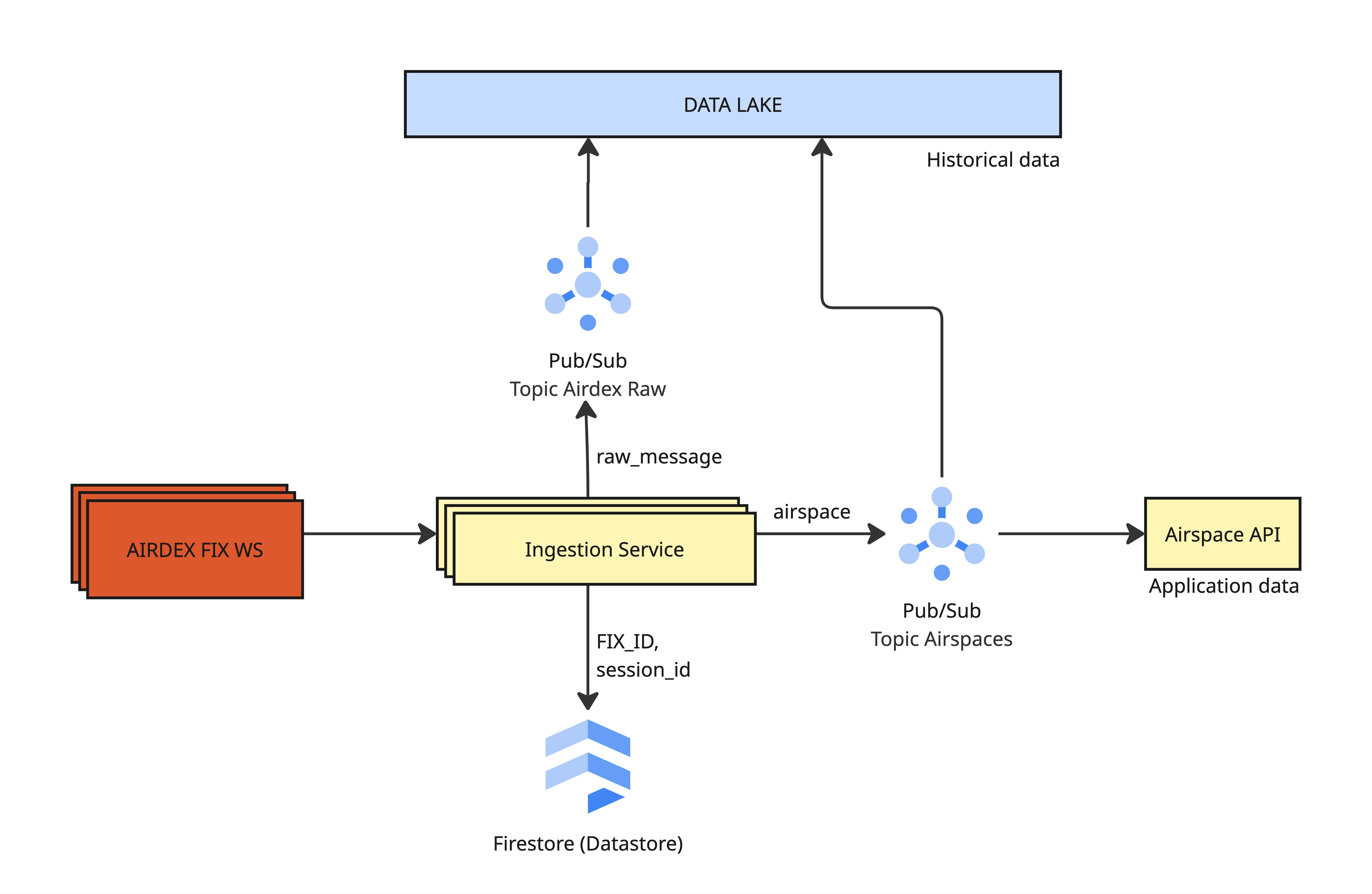
The ingestion will be done through standalone ingestion service. This architectural choice supports the requirements for long-lived connections and low latency.
1. Connection & Concurrency Model
- Guaranteed Delivery: We will utilize AirDEX’s guaranteed delivery mode.
- Serial Processing: Message-level acknowledgments (ACKs) enforces processing one message at time. We will deploy one ingestion service instance per AirDEX Fix (feed source).
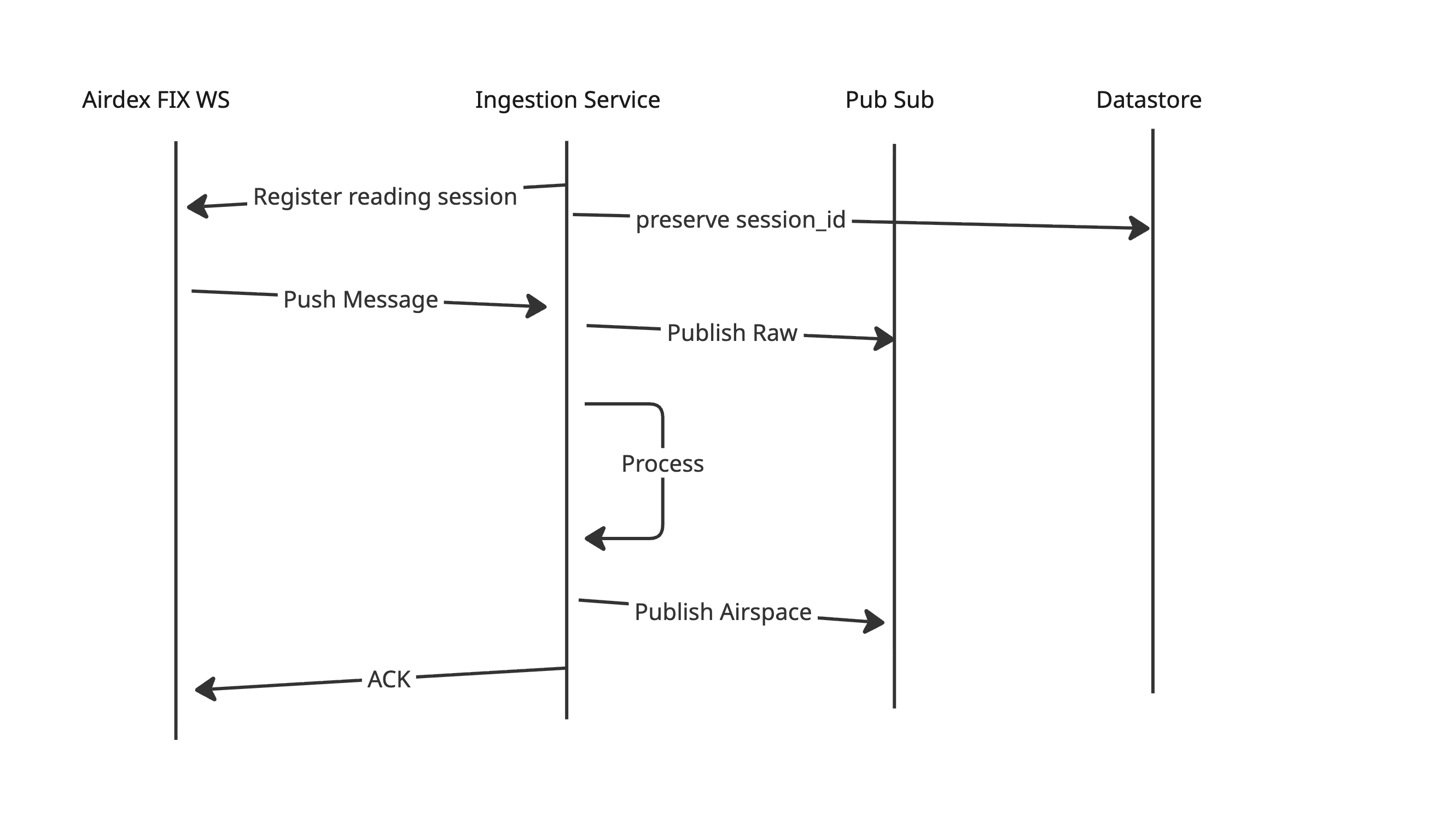
The service sends ACK only if it succesfully process and publish the data, therefore if anything goes wrong the AirDEX will push the same message after reconnect. In case of invalid messages - the service can implement a logics that the message is dropped after few unsuccessfully approaches for processing to not block the pipeline.
2. Data Pipeline
- Data Archival: Raw JSON messages from the websocket are immediately published to a “Raw” Pub/Sub topic and archived in the Data Lake. This ensures full auditability and allows for historical replays. The same goes to processed messages from the Pub/Sub airspace topic.
- Enrichment & Distribution: The Ingestion Service transforms raw events into production-grade
Airspacemodel. These standardised events are published to theairspacesPub/Sub topic. - Serving: The downstream Airspace API consumes the
airspacestopic to update its internal state and serve fresh Mapbox Vector Tiles (MVT) to consumers.
Pub/Sub message schema structure contains 2 fields containing unique information: data and attributes. The design assumes that within the message attributes there are embedded information about FIX_ID and SESSION_ID. If Pub/Sub consumer detects a new session-id it must invalidate data connected to old session.
| Name | Type | Values | Description |
|---|---|---|---|
| action | string | insert / update / delete | Action done on Airspaces table. |
| fix-id | string | example: PA / VA | AirDEX FIX (area of operation) code. |
| session-id | string | uuid | UUID of a current active AirDEX session |
| timestamp | string | example: 2023-07-20 09:04:14.331000 | Parameter that indicates when change happen on the table. |
| version | integer | Version number for message schema |
3. Resumability & State Management
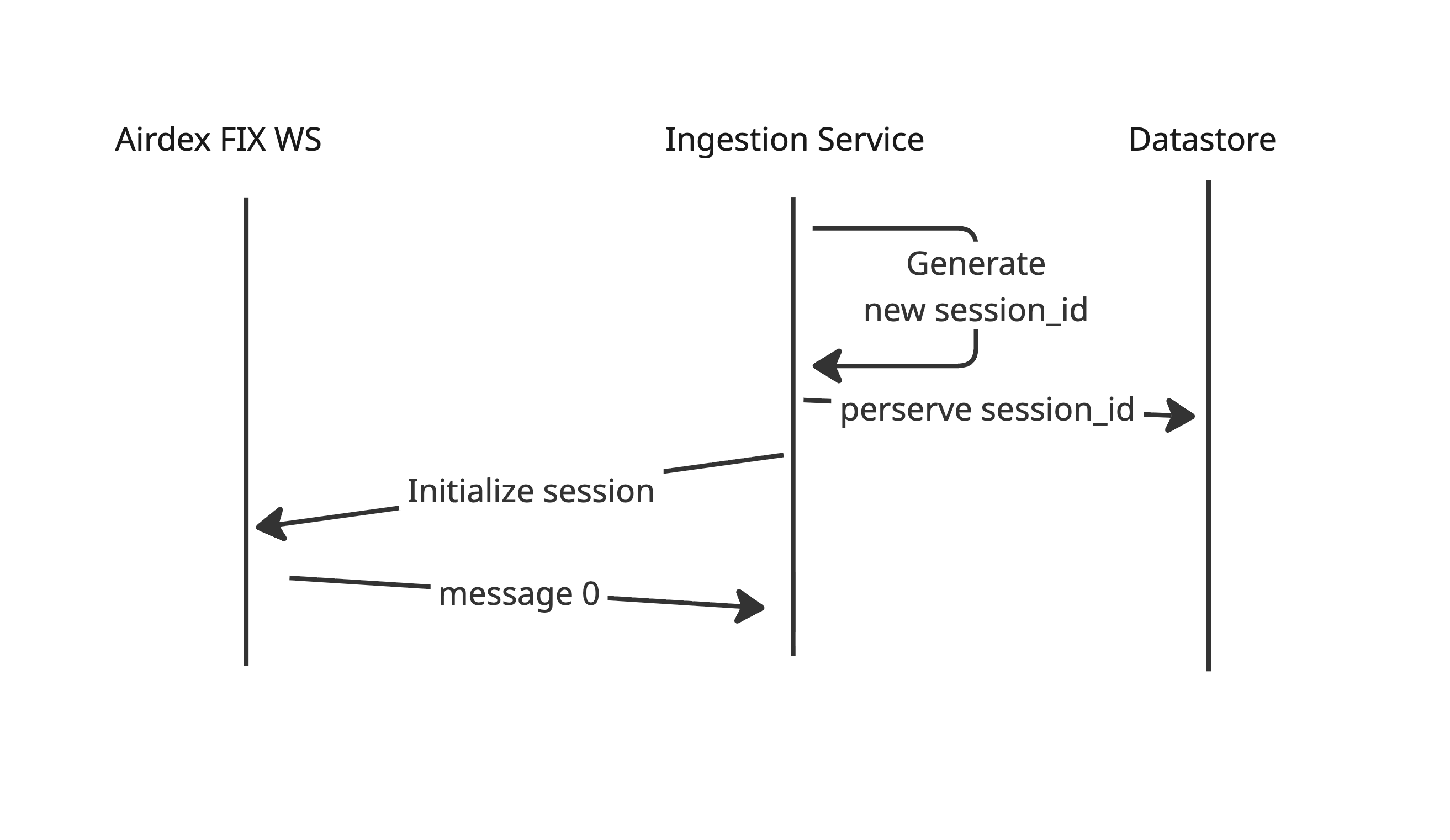
- Session Persistence: To survive service restarts, deployments, or crashes, the service must preserve the active AirDEX
session_id. - Firestore Backend: We will use Firestore to persist the state. specifically the mapping pair of
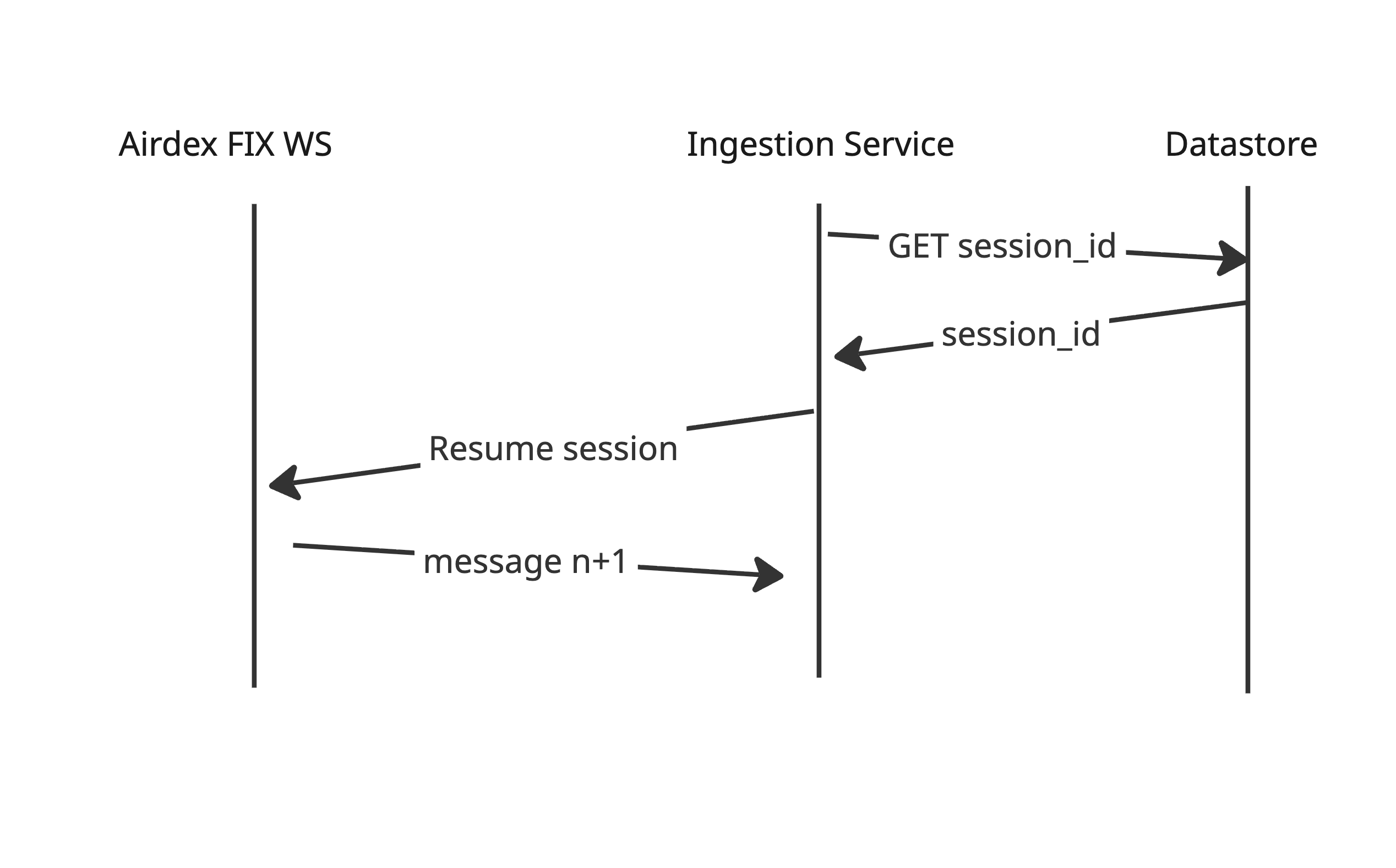
{fix_id: session_id}. - Recovery Strategy: On startup, the service reads Firestore to retrieve the active
session_idfor its assigned Fix ID, allowing it to resume the stream from where it left off without data loss.
Consequences
The writes are handles outside of process flow, therefore the service has minimal latency impact. Main latency sources are:
- Pub/Sub
- Airspace API (Postgres, Charger)
- Network transfer (Ingestion->Pub/Sub , Pub/Sub → Charger, Charger->Postgres, Postgres->Airspace API, AirspaceAPI->GeoData Service)
The ingestion service does not maintain the dataset internally, therefore the pub/sub consumers must implement idempotent reads to survive duplicated messages. However this behaviour was already introduced by Pub/Sub itself so the services shall be ready for that.
The service consumers must be prepared for re-streaming events with the failures. The re-stream could be detected with new session id attached to airspace.
Alternatives Considered
Airflow DAG vs Standalone Service
Most of the processing pipelines can be achieved with Airflow DAG, however Airflow adds extra latency for the processing (picking up the task by scheduler and spawning new pod on k8s). Also due to Airflow Design it is not well suited to continuous running jobs.
One instance of service consume multiple websockets in separate threads
This is valid design, especially if the update traffic is low, although it would enforce more complex solution due to concurrency management. Also in case of service crash, all of the injection processes would fail together.
Dataset storage within ingestion service
The Ingestion Service does not store the ingestion data in the database but rather process and pushes it forward. This design was chosen since the Airdex already provides resumable streams with ACK. Therefore there is no risk of data loss. There are few reasons why we might want to include database anyways:
- Deduplication - The service could deduplicate messages incoming from websocket, however the pub/sub brings at-least-once delivery model so the consumer must do that anyways.
- Audit change history / analytics / data quality - The service could store the data is db for historical purposes, however the datalake is better suited and cheaper option for those tasks.
The resigning from DB also simplifies the whole design since it removes the dual-write problem.
Session state storage
The service must persist it’s session id to resume connection with websocket from last processed message. There are few alternatives for Firestore - either micro Postgres or GCS artifact.
- Micro Postgres would require us to maintain a postgres instance which would contain just few records (literally one atm). Since there is not need of DB for any other purposes within the service this seem to be an overkill.
- GCS might be a good option but it require more complex configuration in order to perserve the state a file (eg. preventing the directory to be removed etc). Also there would need to be a specific protocol designed to update a file since GCS does not guarantee concurrent updates
Firestore for few key-value pairs is a simple and no-cost solution.
Decuple ingestion from processing
In general separating ingestion from processing is a good pattern although in shines when at least one of cases bellow appear:
- Data source is stateless
- Data source lacks CRUD
- Processing is expensive
If any of those situations appear the ingestion works as a work queue. However in case of airdex non of those is true.
- The data is served as a stream of changes with create update delete information.
- The Airdex maintain subscribers state so no data is lost
- The data processing is trivial, even multiple retries would take significantly less time than network transfer connected with pub/sub
Formal Impact
- UTM Airspace Charger
- UTM Airspace API
- GeoData Service