Flight Traffic Exchange Architecture Proposal And Design Details
Originally
ADR--0133--Flight Traffic Exchange Architecture Proposal and Design Details (v5) · Source on Confluence ↗ADR: Flight Traffic Exchange Architecture
| Traceability Links | |
|---|---|
| Jama Requirements | https://droneup.jamacloud.com/perspective.req#/containers/1133923?projectId=87 |
| Jira Tasks | CORE-2564 |
Context
Context
ATOMx requires a unified “single pane of glass” view for flight traffic data aggregation and distribution. We need to define a scalable, reliable architecture for telemetry exchange that can:
- Ingest telemetry from multiple sources (operators, third-party providers, surveillance systems)
- Process and fuse data in real-time with low latency (< 100 ms P99)
- Distribute processed traffic data to multiple consumers
- Support high availability and fault tolerance
- Scale horizontally to handle 3,000+ concurrent flights per metropolitan area
- Provide data replay and historical query capabilities
The architecture must meet aviation safety standards and support both commercial UTM operations and tactical/defense applications.
Decision
We will adopt the Traffic Service architecture from AirMap UTM Legacy Platform enhanced with Write-Ahead Log (WAL) pattern using Kafka.
Architecture Diagram
Mermaid diagram
flowchart TD
subgraph providers["PROVIDER LAYER"]
UDP["UDP Provider"]
TELEM["Telemetry Service<br/>(gRPC)"]
FA["FlightAware Provider"]
SWIM["FAA SWIM Provider"]
THALES["Thales Provider"]
ADSB["ADS-B Provider"]
end
subgraph kafka["KAFKA - WRITE-AHEAD LOG"]
RAW["Raw Observations Topic<br/>(Partitioned by Source)"]
subgraph fusion["Fusion Workers (Consumer Group)"]
W1["Worker 1"]
W2["Worker 2"]
WN["Worker N"]
REDIS["Redis Cluster<br/>Track State"]
end
FUSED["Fused Observations Topic<br/>(Partitioned by Track ID)"]
end
subgraph output_processors["OUTPUT PROCESSORS"]
WS_PROC["WebSocket<br/>Processor"]
MQTT_PROC["MQTT<br/>Processor"]
AST_PROC["ASTERIX<br/>Processor"]
TAK_PROC["TAK/CoT<br/>Processor"]
PERSIST_PROC["Persistence<br/>Processor"]
ARCHIVE_PROC["Archive<br/>Processor"]
end
subgraph destinations["DESTINATIONS"]
WEB["Web Clients"]
IOT["IoT Devices"]
ATM["Legacy ATM"]
TAK["Tactical<br/>Systems"]
INFLUX["InfluxDB<br/>Time-Series"]
S3["S3 / Cold<br/>Storage"]
end
%% Provider to Kafka
UDP --> RAW
TELEM --> RAW
FA --> RAW
SWIM --> RAW
THALES --> RAW
ADSB --> RAW
%% Kafka processing flow
RAW --> fusion
W1 --> REDIS
W2 --> REDIS
WN --> REDIS
REDIS --> FUSED
%% Fused to Processors
FUSED --> WS_PROC
FUSED --> MQTT_PROC
FUSED --> AST_PROC
FUSED --> TAK_PROC
FUSED --> PERSIST_PROC
FUSED --> ARCHIVE_PROC
%% Processors to Destinations
WS_PROC --> WEB
MQTT_PROC --> IOT
AST_PROC --> ATM
TAK_PROC --> TAK
PERSIST_PROC --> INFLUX
ARCHIVE_PROC --> S3
style kafka fill:#e1f5ff
style providers fill:#fff4e1
style output_processors fill:#f0f0f0
style destinations fill:#e8f5e9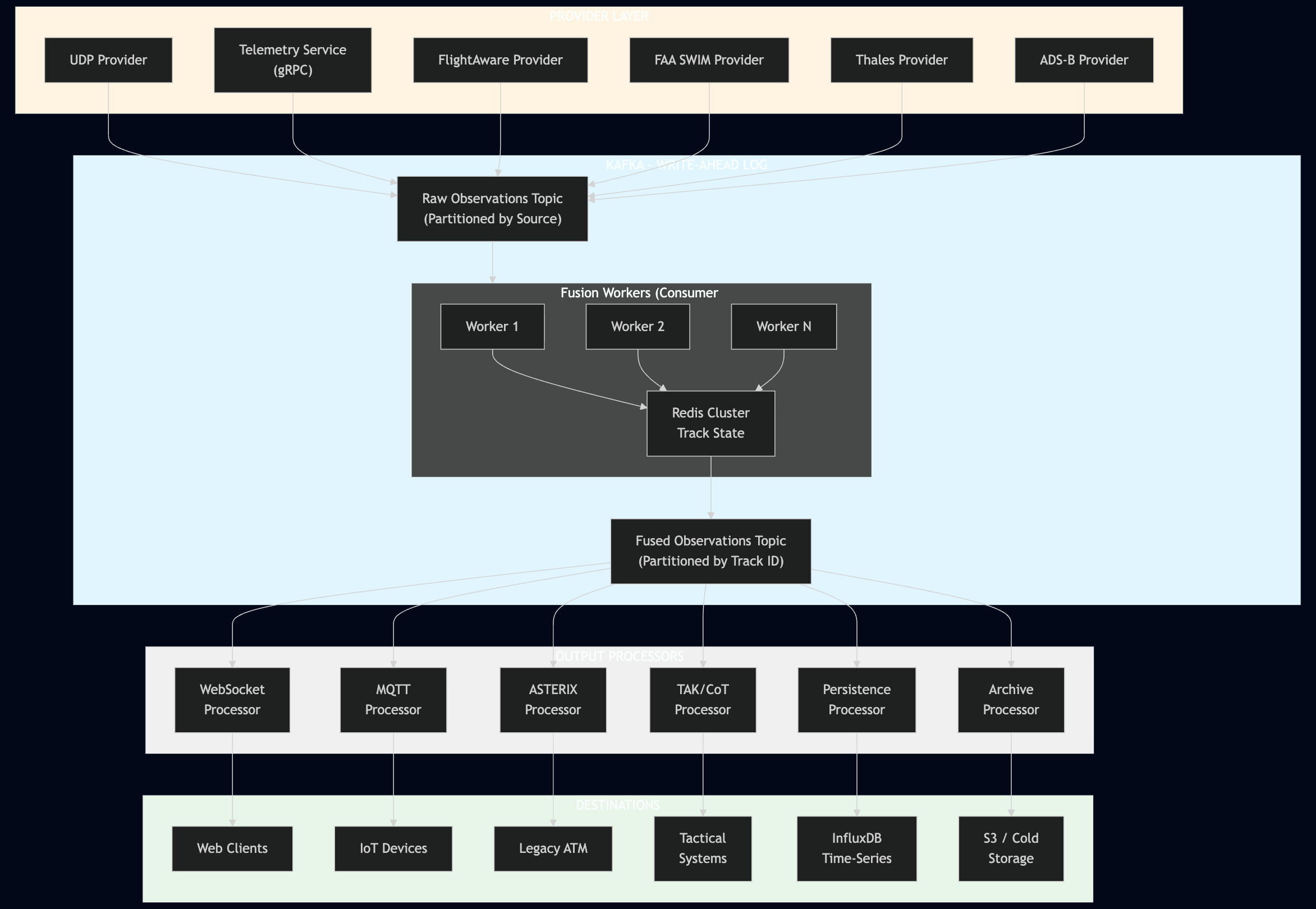
Data Flow
- Ingestion: Providers receive telemetry from various sources and publish to Kafka
raw-observationstopic. - Fusion: Stateless Fusion Workers consume raw observations, correlate tracks using Redis, and publish to
fused-observationstopic. - Distribution: Processors consume fused data via consumer groups and distribute to their respective channels.
- Storage: Persistence and Archive processors store data for historical query and replay.
Core Architecture Components
1. Provider Layer
UDP Provider: Direct telemetry ingestion from operators.
Telemetry Service Provider: gRPC bidirectional streaming for Remote ID compliance.
Third-Party Adapters: FlightAware, FAA SWIM, PASSUR, Thales, and other surveillance providers.
Protocol Support: ADS-B, ASTERIX, ASTM F3411 Remote ID, vendor-specific APIs.
Authentication & Authorization:
- All connections must meet FedRAMP High requirements for authentication/authorization.
- Push Providers (UTM telemetry): Authenticate to DroneUp’s FedRAMP-compliant IDP.
- Pull Providers (FlightAware ADS-B, Flarm): DroneUp authenticates to provider’s IDP.
- Shared authentication layer similar to Uncrew system architecture with a shared IAM service.
- Provider-specific implementation based on vendor IDP configuration.
2. Write-Ahead Log (Kafka)
Raw Observations Topic: All incoming telemetry preserved with full provenance.
Fused Observations Topic: Track-fused data for consumer distribution.
Event Sourcing: Complete audit trail and replay capability.
Ordering Guarantees: Per-partition ordering for track consistency.
Retention: 7 days default for operational replay, configurable per deployment.
Deployment Preference: Self-hosted Kafka preferred over Confluent Cloud for latency optimization:
- Reduces external cloud connection latency.
- Better control over partition configuration and performance tuning.
- FedRAMP High compliance easier with self-deployment.
Expected Performance: 25–50 ms producer-to-consumer latency.
- Note: AI-generated estimates requiring real-environment validation.
- Optimizable through proper partition configuration.
- Latency measured from message write to consumer-ready (excluding consumer processing).
Delivery Guarantees: At-least-once delivery (exactly-once NOT required).
- Message duplication has no negative consequences for telemetry data.
- Simpler implementation with better performance vs exactly-once.
3. Fusion Layer
- Stateless Fusion Workers: Scale horizontally via Kafka partitions.
- Redis Cluster: Distributed track state for multi-source correlation.
- Track Matching: ICAO address (primary), callsign (secondary), position-based correlation.
- Trust Scoring: Authenticity, plausibility, and consistency scoring per observation.
4. Processor Layer (Consumers)
- WebSocket Processor: Real-time streaming to web clients.
- MQTT Processor: IoT device distribution.
- ASTERIX Processor: Legacy ATM system integration.
- TAK Processor: Cursor-on-Target for tactical applications.
- Persistence Processor: InfluxDB time-series storage.
- Archive Processor: Long-term cold storage.
- Receive auth context from centralized Auth Service, enforce RBAC/ABAC before distribution if it applicable.
- Processor-level filtering (tenants only receive authorized data) if it applicable.
- Geographic Filtering: Processor layer enforces jurisdiction-based filtering per consumer.
5. Distribution Pattern
- Kafka Consumer Groups: Automatic load balancing and failover.
- Processor Isolation: Independent scaling and failure domains.
- Back-pressure Handling: Graceful degradation without blocking other consumers.
Key Architectural Patterns
Event-Driven Architecture
Provider → Kafka (Raw) → Fusion Workers → Kafka (Fused) → Processors → ConsumersHorizontal Scalability
- Providers: Scale independently per data source.
- Fusion Workers: Scale via Kafka partitions (N workers ≤ N partitions).
- Processors: Scale via consumer groups with automatic rebalancing.
Fault Tolerance
- Provider isolation: Failure in one provider doesn’t affect others.
- Kafka replication: 3x replication factor for data durability.
- Consumer resilience: Failed processors don’t block others.
- Automatic reconnection: Exponential backoff with max 30 s interval.
Implementation Strategy
- Modular Development: Component-by-component implementation allowing language flexibility.
- Performance-Critical Components: Rust implementation for latency-sensitive fusion workers.
- Standard Components: Go implementation for providers and processors.
- Incremental Migration: Start with existing code, migrate to optimized implementations as needed.
Observability & Monitoring
System Observability (Non-Functional Requirements):
- Performance metrics: Latency, throughput, partition lag.
- Component health: CPU, memory, connection status.
- Kafka metrics: Consumer group lag, rebalance frequency.
- Trace long-lived connections (not individual telemetry messages).
- Connection disconnections and transmission metrics.
Consequences
Positive
- ✅ Proven Architecture: Reuses battle-tested AirMap traffic service patterns.
- ✅ Horizontal Scalability: Kafka partitioning enables linear scaling.
- ✅ Event Sourcing: Complete audit trail and replay capability.
- ✅ Fault Isolation: Component failures don’t cascade.
- ✅ Real-Time Performance: Sub-100 ms latency achieved with in-memory processing.
- ✅ Flexibility: Processor pattern allows easy addition of new consumers.
- ✅ Aviation Compliance: Supports DO-278A traceability and audit requirements.
Negative
- ⚠️ Operational Complexity: Kafka cluster management requires expertise.
- ⚠️ Infrastructure Cost: Redis Cluster + Kafka + InfluxDB increases operational overhead.
- ⚠️ Learning Curve: Teams unfamiliar with Kafka need training.
- ⚠️ Data Latency: Small latency increase vs. direct point-to-point (mitigated by optimization).
Mitigations
Complexity Management
- Managed Kafka service (Confluent Cloud, AWS MSK) for production.
- Infrastructure-as-Code (Terraform) for reproducible deployments.
- Comprehensive runbooks and monitoring.
Cost Optimization
- Auto-scaling based on partition lag and consumer group metrics.
- Tiered storage for Kafka (hot in-memory, warm on SSD, cold on S3).
- Right-sizing of Redis cluster based on active track volume.
Team Enablement
- Kafka training workshops.
- Reference implementations and code examples.
- Internal documentation and architecture guides.
Compliance Notes
DO-278A Software Assurance
- Event sourcing provides complete traceability per DO-278A requirements.
- Kafka write-ahead log enables reconstruction of system state for failure analysis.
- Bi-directional traceability from requirements to implementation via partition keys and message metadata.
FedRAMP High
- Encryption at rest: Kafka encryption + Redis TLS.
- Encryption in transit: TLS 1.3 for all inter-service communication.
- Audit logging: All message flows logged with boundary crossing controls.
- Access control: RBAC/ABAC filtering at processor layer.
ASTM F3548-21 Compliance
- Strategic Deconfliction: Track fusion provides conflict detection inputs.
- Operational Intent Exchange: Kafka topics for USS-to-USS communication.
- Data Quality: Trust scoring and validation per ASTM requirements.
Alternatives Considered
1. Direct Point-to-Point (Current AirMap without WAL)
Pros: Lower latency, simpler architecture.
Cons: No replay capability, difficult synchronization, no ordering guarantees.
Reason for Rejection: Doesn’t meet replay and synchronization requirements.
2. Traditional Database-Centric Architecture
Pros: Familiar technology, simpler operations.
Cons: Database becomes bottleneck, poor horizontal scaling, high latency.
Reason for Rejection: Cannot achieve latency requirements at scale.
3. Custom Message Queue Implementation
Pros: Full control over implementation.
Cons: High development cost, reinventing solved problems, maintenance burden.
Reason for Rejection: Kafka provides production-ready solution with better ecosystem support.
4. Hybrid gRPC + Kafka Approach
Architecture: Keep existing gRPC streaming for real-time distribution while adding Kafka WAL for durability and replay.
Providers → Collector (gRPC) → [Local WAL + Kafka (async)] → Processors (gRPC)
↓
Replay Service (Kafka)Implementation Details:
- Providers maintain lightweight ring buffers (10–30 seconds) for retry on transient collector failures.
- Collector asynchronously publishes to Kafka for distributed durability and replay.
- Real-time processors receive data via gRPC streams (existing pattern).
- Historical replay reads from Kafka topics.
Pros:
- ✅ Preserves existing gRPC architecture and minimal latency.
- ✅ Kafka used only for durability/replay (reduces latency impact).
- ✅ Provider ring buffers handle transient failures without full WAL.
- ✅ Emergency/low-latency bypass available via direct gRPC.
- ✅ Gradual migration path from current AirMap architecture.
Cons:
- ⚠️ Dual data paths increase complexity (gRPC + Kafka).
- ⚠️ Risk of inconsistency between real-time (gRPC) and historical (Kafka) views.
- ⚠️ Still requires managing both gRPC streaming infrastructure AND Kafka.
- ⚠️ Ordering guarantees harder to maintain across two systems.
- ⚠️ Additional operational overhead for two message systems.
Latency Impact:
- Real-time path: No additional latency (pure gRPC).
- Kafka write: 25–50 ms async (doesn’t block real-time).
- For 1–5 second update cycles, async Kafka write is negligible.
Decision Status: Deferred as Migration Strategy
This hybrid approach is not rejected but rather deferred for strategic implementation:
Use Case 1: Migration Path
- Phase 1: Start with hybrid (minimal disruption to existing AirMap gRPC architecture).
- Phase 2: Gradually shift consumers from gRPC to Kafka consumers.
- Phase 3: Eventually deprecate gRPC streams when all consumers migrated.
- Benefit: Reduces risk by allowing incremental migration with rollback capability.
Use Case 2: Latency Fallback
- If production testing reveals Kafka latency exceeds requirements (> 100 ms P99).
- Critical real-time paths (emergency alerts, collision warnings) stay on gRPC.
- Non-critical paths (logging, analytics, replay) use Kafka.
- Benefit: Meets aggressive latency SLAs while maintaining durability.
If Kafka latency proves problematic, this hybrid architecture becomes the fallback plan with a well-documented implementation strategy.