Onboard Geodata
Originally
ADR-0097-OnBoard-Geodata (v15) · Source on Confluence ↗Geodata Services Cache Architecture
Context
We must implement a geodata cache service which can be deployed in-cloud and on-board the drone:
- Geodata is a required input for the pathfinding algorithm and the planned onboard perception system
- We cannot rely on a network connection always being available
- Even when a connection is available, constantly fetching geodata over the network would be an inefficient use of limited bandwidth
Requirements
- As stated above, we must be able to deploy this service in-cloud and on-board the drone.
- Since we want to implement a multi-layer cache, we should also be able to deploy this service in the cloud to serve as another tier.
- Updated geodata must reach the onboard cache quickly, so that the pathfinder can react. Specifically, [the cache should be updated within 10 seconds of a change in source data](confluence-title://LA/Consumption (inc. Caching) of Data Streams).
- We can’t expect to save bandwidth if we refresh the entire cache every 10 seconds, so updates to specific cache entries must be pushed to the cache (or the cache must be told to request an updated entry) when a change occurs.
- The cache should be granular. We can’t just send the entire mission area or hub area when something is updated, since that would be an inefficient use of bandwidth.
- The cache must be populated before a mission starts. This includes at least the mission’s contingency volume.
- Pathfinder makes REST requests, so this must expose a REST interface for pathfinder to use.
- It is inevitable that network outages will occur, so this service must tolerate a loss of connection to upstream. However, once a connection is reestablished, updates must resume. Updates for any tiles which occurred upstream while the connection was down must be communicated once the connection is back so that we do not continue to operate with out-of-date geodata.
Decision
Implement our own cache service
We will implement our cache service from scratch (or mostly from scratch), with updates pushed from upstream. We will use BadgerDB for local storage, since it offers configurable memory footprint, concurrent transactions, and on-disk persistence, as well as backups which will be useful if we want to use it to create test fixtures like we’ve done with Nginx in the past.
Consequences
Advantages
- We will have the flexibility to get the behavior we desire from geodata service, since we are implementing most of it ourselves.
- This will avoid many of the interprocess/network requests when compared with the “NGINX with sidecar” approach.
- Pushing tiledata with update notifications means we get some built in atomicity.
- We can have only one process for the cache, as opposed to two if we use a standalone option like Nginx for caching.
Disadvantages
- This will be somewhat more development effort when compared with an option like using our current Nginx based cache with a sidecar notification service. Nginx would provide us with a free
Getmethod via the REST interface. Pathfinding already uses REST to talk to the webcache, and we will have to reimplement this interface ourselves. - We are not using an off-the-shelf solution, which means we are responsible for all bugs. Implementing caching is regarded as difficult. We are implementing a push-based design, which we hope makes this simpler, but there are still many opportunities to make mistakes.
Alternatives considered
NGINX with side(car) notification service
We could re-use our NGINX webcache, and implement another service which subscribes to notifications for updated cache entries. This notification service would make a request to NGINX which would fetch the updated tile.
The main advantages of this approach are
- faster implementation
- we can use tried-and-true NGINX without modifications
Why rejected
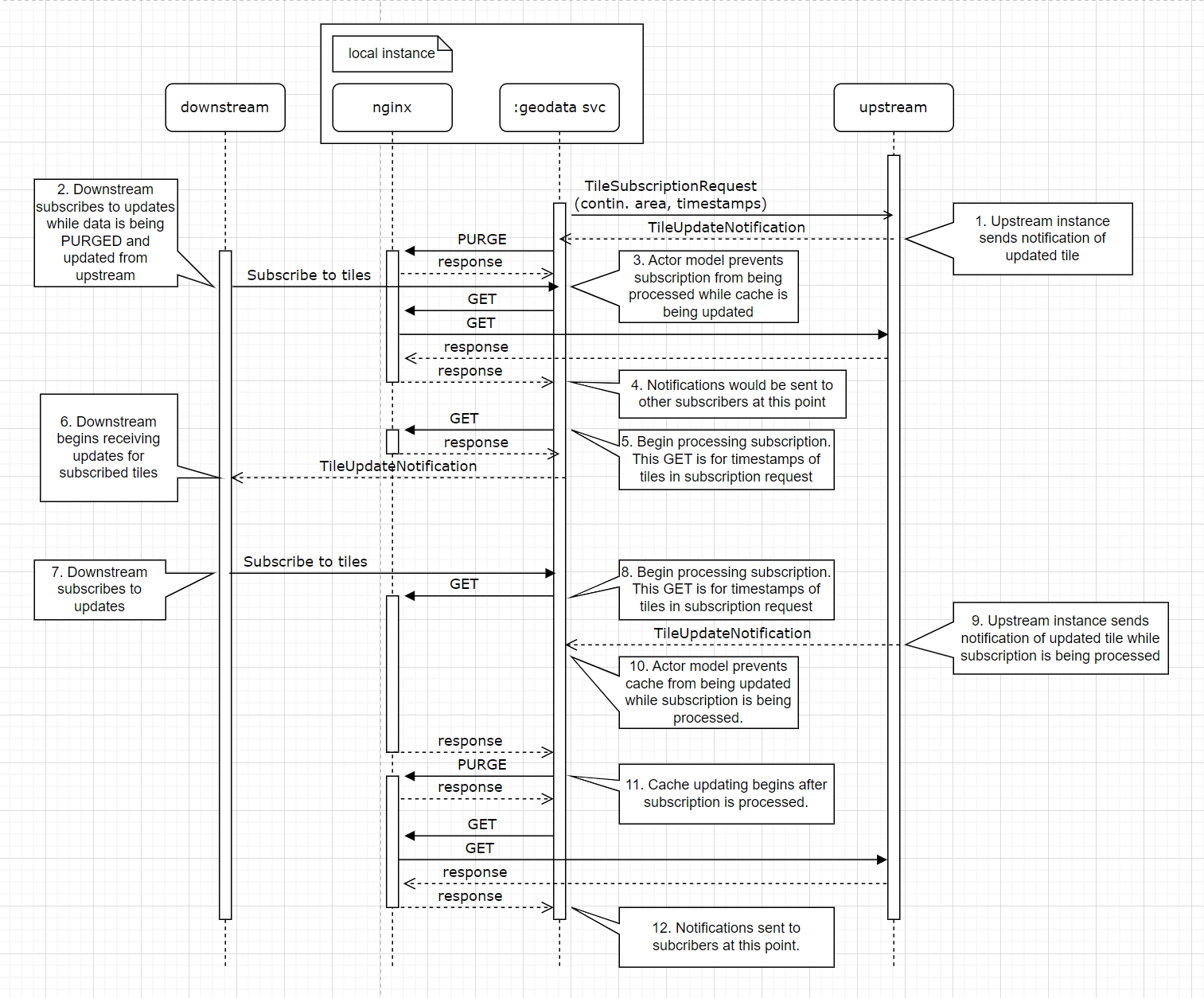
- A major issue with this approach is that it requires us to separately PURGE tiledata from the local cache and then GET it from upstream. If we were to lose our network connection between the PURGE and GET, we would be missing a tile.
- Multiple processes
- Every update requires several network trips. For each layer of the cache, there would be at least the notification from the upstream to the notification service, the request from the notification service to NGINX, NGINX request to upstream for the updated tile, and the response with the updated tile.
This is a sequence diagram of the interactions between NGINX, the sidecar notification service, and up/downstream nodes when a tile is updated upstream.
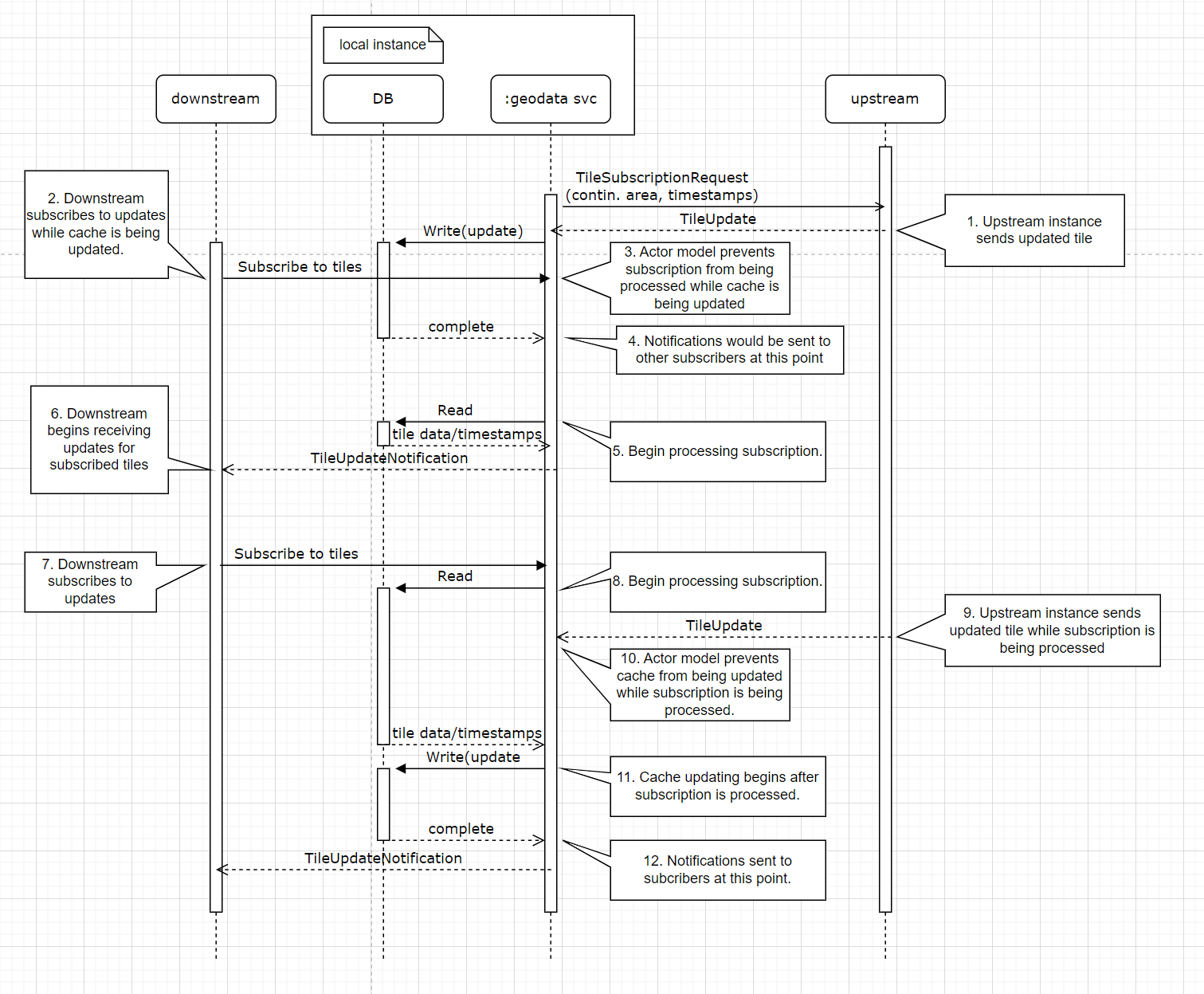
This is a sequence diagram of the interactions between nodes of a push-based cache when a tile is updated upstream.
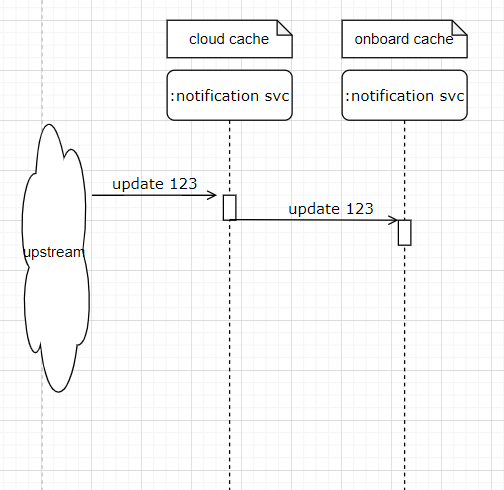
NGINX or other open-source cache with custom extension
We could extend an open-source option to work with our gRPC notification scheme.
Advantages:
- Ideally, we would get the ease of use and reliability of a ready-made cache, with our specific desires for gRPC notifications
- Only one service
Why rejected
- This would likely be the most difficult to implement for the least benefit. We were not able to find an option with the push-based update scheme we would like, so we would still have to implement our notification service, but we would be required to do so in the context of whatever open-source option we choose
Push cache/notification design
We have to carefully consider the design of this system, since it will be how we ensure cache validity. It is necessary for any of the above options, since we will always require some form of downward-flowing notifications or cache updates. The below is written assuming that notifications contain updated tile data (i.e. the “Implement our own cache service” option), but if we decide to do the “NGINX with side(car) notification service” option, this wouldn’t be the case.
Proposed RPC Interface
service GeodataService {
rpc SubscribeToTiles (TileSubscriptionRequest) returns (stream TileUpdate);
rpc GetTiles (TileIDs) returns (TileUpdates);
}
message TileSubscriptionRequest {
repeated TileID tile_ids = 1;
repeated int64 timestamps = 2;
}
message TileID {
int x = 1;
int y = 2;
int z = 3;
string category = 4;
}
message TileIDs {
repeated TileID tile_ids = 1;
}
message TileUpdate {
TileID tile_id = 1;
int64 timestamp = 2;
TileValue value = 3;
}
message TileUpdates {
repeated TileUpdate tile_updates = 1;
}
message TileValue {
repeated PixelRow rows = 1;
}
message PixelRow {
repeated Pixel pixels = 1;
}
message Pixel {
char val = 1;
}GetTiles and SubscribeToTiles
The GetTiles RPC allows a client to get the current value and timestamp for a set of tiles. The SubscribeToTiles RPC allows a client to subscribe to updates for a list of tiles, returning a stream via which updates for tiles will arrive. When considering only the needs of the onboard cache, the GetTiles RPC may not be strictly necessary. The onboard cache, and likely most clients, will need to subscribe, and can “get” the tiles they’re interested in by passing 0 for the offset when subscribing. In the case where they’re re-subscribing to a tile and already have something saved locally, they can pass the offset of the local tile and may or may not receive an update immediately. However, other clients may need to get only the current value of a tile or tiles. Additionally, it may be useful to have a synchronous way to get the value of a tile or tiles. For instance, the onboard cache must be populated with all tiles in the contingency area before a mission is allowed to start, and the synchronous GetTiles may simplify that, since we would otherwise have to use the SubscribeToTiles RPC and wait until an update had come through the stream for every tile in the contingency area.
Notification handling
Each layer of the cache receives notifications of updated items to which it is subscribed from upstream. These notifications contain the ID of the tile, a timestamp, and the updated tile data. The timestamp serves to uniquely identify each “version” of the tile, and allows data for the same tile to be compared based on recency. The 0 timestamp is used as a sentinel value to indicate that a client who is subscribing to a tile does not already have any version of it stored. When a notification is received, the updated tile and its timestamp are stored in the local database, and the notification is repeated to each of the downstream subscribers to that tile, who continue the process in the same manner.
Subscription handling
When a downstream client subscribes to a tile, they must send a timestamp with the SubscribeToTiles RPC, as described above. If the timestamp is the sentinel value indicating that the downstream client does not have a cached version of the tile (i.e. 0), the service should send its cached version of the tile to the subscriber. If the timestamp is not the sentinel value, the service will compare that timestamp with the timestamp of the tile stored in its database, and if the incoming timestamp is less recent than the stored timestamp, it will send its tile to the subscriber, since it is more recent. If it’s the same, it does not need to send a notification to the subscriber for that tile until it the tile receives an update from upstream. If it is greater, this would indicate an issue with the geodata service, since upstream nodes should always receive updates before downstream nodes.
Options for local storage
Several options have been considered for managing memory and storage use of the geodata service. These include out-of-process options like Redis and Memcached, and in-process ones like BadgerDB, RocksDB, and BoltDB. Since we are implementing our own notifications for the geodata service, in the case where we implement a push-based cache rather that the “Nginx with sidecar” option, whatever we pick would be used mainly as a key value store. For that reason, it is appealing to choose a simpler in-process option. We would not have a use for the distributed capabilities of Memcached, or the redundancy of Redis, since neither of these allow us the heirarchical cache that we desire. BadgerDB is especially appealing since it allows configuration of in-memory cache size, so it is recommended for the geodata service.
Avoiding race conditions
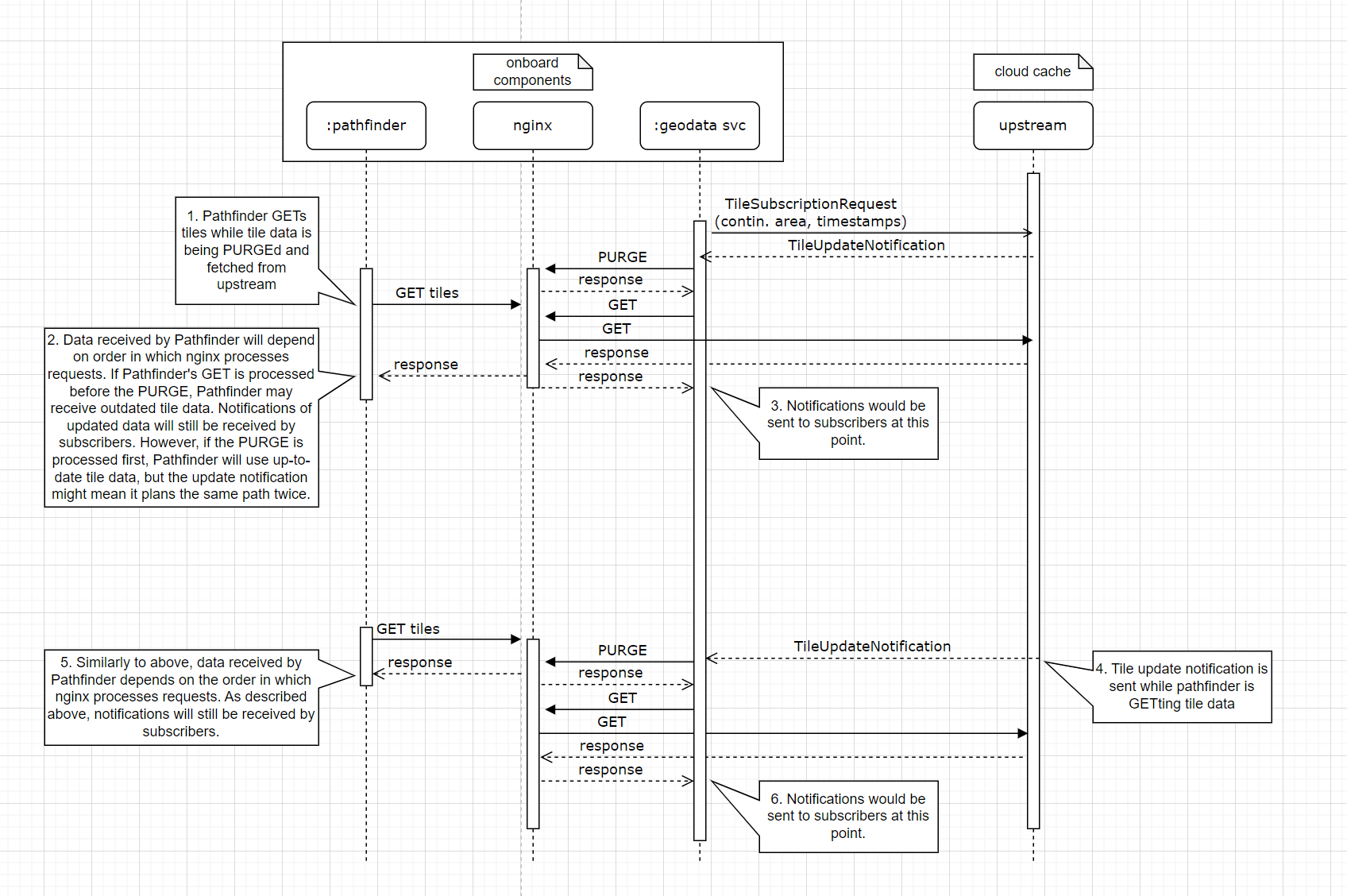
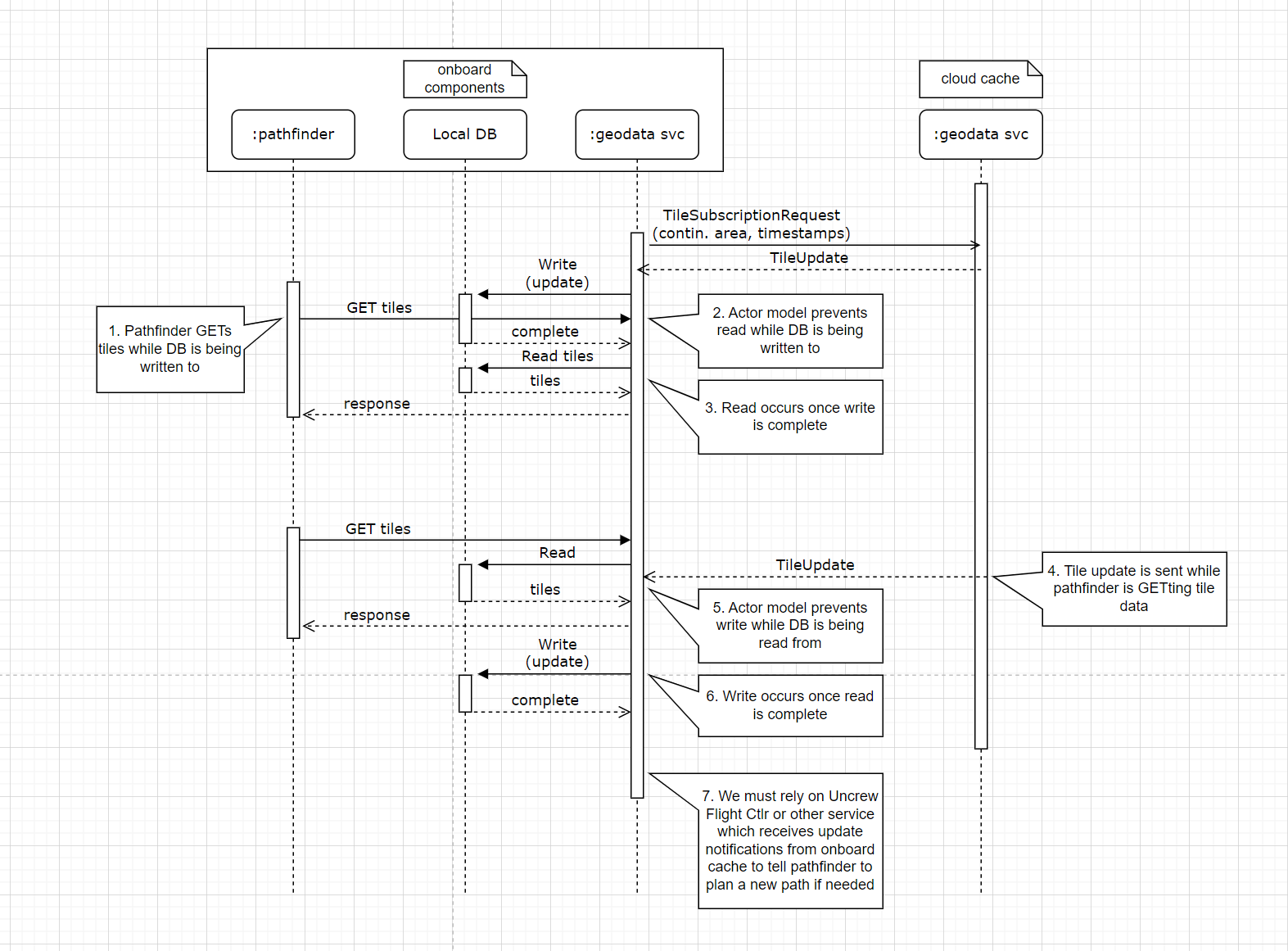
There are potential race conditions if we handle notifications and subscriptions concurrently. For instance, the following may occur:
- A downstream calls the
SubscribeRPC for a tile - The value of the tile is read from the database
- An update for the tile is received from upstream, stored in the database, and passed on to downstream subscribers
- The old value is sent to the new subscriber
This is similar to an example given in this article. As described there, we can avoid situations like this by processing subscriptions and notifications sequentially, and ensuring that any action leaves the cache in a coherent state. We can still fairly easily process new subscriptions in parallel if necessary, since these will only require read-only access to the database. We can likely process notifications in parallel if necessary, as long as we don’t process two notifications for the same tile concurrently.
What is a coherent state?
- The database reflects the data received in all processed notifications
- For every tile to which a downstream subscriber whose subscription has been processed subscribes, the downstream subscriber has either been sent a notification with the tile information in the database, or already has that information based on the timestamp they sent when they subscribed.
A coherent state may also have unprocessed subscriptions and notifications. This may be implemented with two FIFO queues.
Handling crashes and disconnections
We can’t rule out that nodes will go offline unexpectedly for some reason, so we must be able to handle this.
Upstream disconnects
In this case, the node must reestablish a connection with the upstream when it comes back online, and then must re-subscribe to all tiles it was subscribed to before upstream disconnected, passing the timestamp of the currently stored version of each tile in its local database, or the sentinel value 0 if there is no currently stored version. This demonstrates that we require a way for nodes to remember their current subscriptions other than the existing connection to upstream, so this information must be stored locally.
Downstream disconnects
We must allow for downstream clients to disconnect, but otherwise don’t need to specially handle this case, since it is expected that this will occur sometimes, like when a drone is powered off.
Recovery from a unexpected termination
Upon restarting after an unexpected termination, the node must first reestablish a connection with upstream. This demonstrates that information about the upstream node which allows the node to connect must be stored on-disk, since it may otherwise be unavailable. It must then re-subscribe to all tiles it was subscribed to before it terminated, passing the timestamp of the currently stored version of each tile in its local database, or the sentinel value 0 if there is no currently stored version, as in the “Upstream disconnects” case. This demonstrates that the list of current subscriptions must also be stored on-disk, so it is accessible on restart. Once it has re-subscribed to all tiles, it can begin handling downstream clients.
What if a node receives a notification, but crashes before it stores the new tile information?
This case is handled as described above. Since the new tile information hasn’t been stored, when the node re-subscribes to the tile, it will pass an out-of-date timestamp, and the upstream node will know to resend the updated tile information.
What if a node receives a notification and stores the new tile information, but crashes before it sends the new information downstream?
In this case, as described above, downstream clients will reconnect to the node when it comes back online, and resubscribe to the tiles that they are interested in. Since they will pass an timestamp older than the one that is stored on the node which crashed, it will know to send a notification with the updated tile information downstream.
How and when will the cache be populated (specifically, the cache on the drone)?
Since we would like the cache to contain at least the contingency volume for a mission, we cannot know what to populate until a mission is assigned. So, the cache should be populated sometime after a mission is assigned.
Note that this requires some service to determine the contingency volume for a mission. This is not in the scope of this ADR.
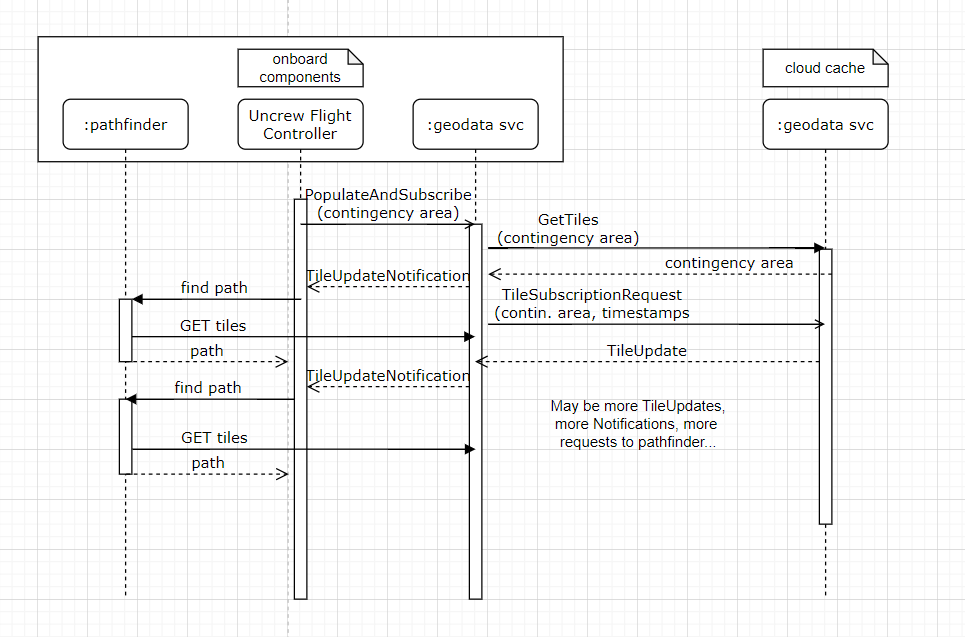
This is a potential interface which can be used to populate an instance of the geodata service, and ensure that the contingency volume is present in the cache before the mission. This would be called from some service external to the geodata service, likely the Uncrew Mission Controller. This external service can call the PopulateAndSubscribe RPC when the tiles in the contingency volume are known. The RPC should return a stream of TileUpdateNotifications, with the first notification in the stream returning once all tiles have been populated in the cache. Further notifications will appear in the stream when tiles in the subscribed area have been updated.
service GeodataService {
rpc PopulateAndSubscribe (PopulateTilesRequest) returns (stream TileUpdateNotification);
}
message PopulateTilesRequest {
repeated TileID tile_ids = 1;
}
message TileUpdateNotification {
}
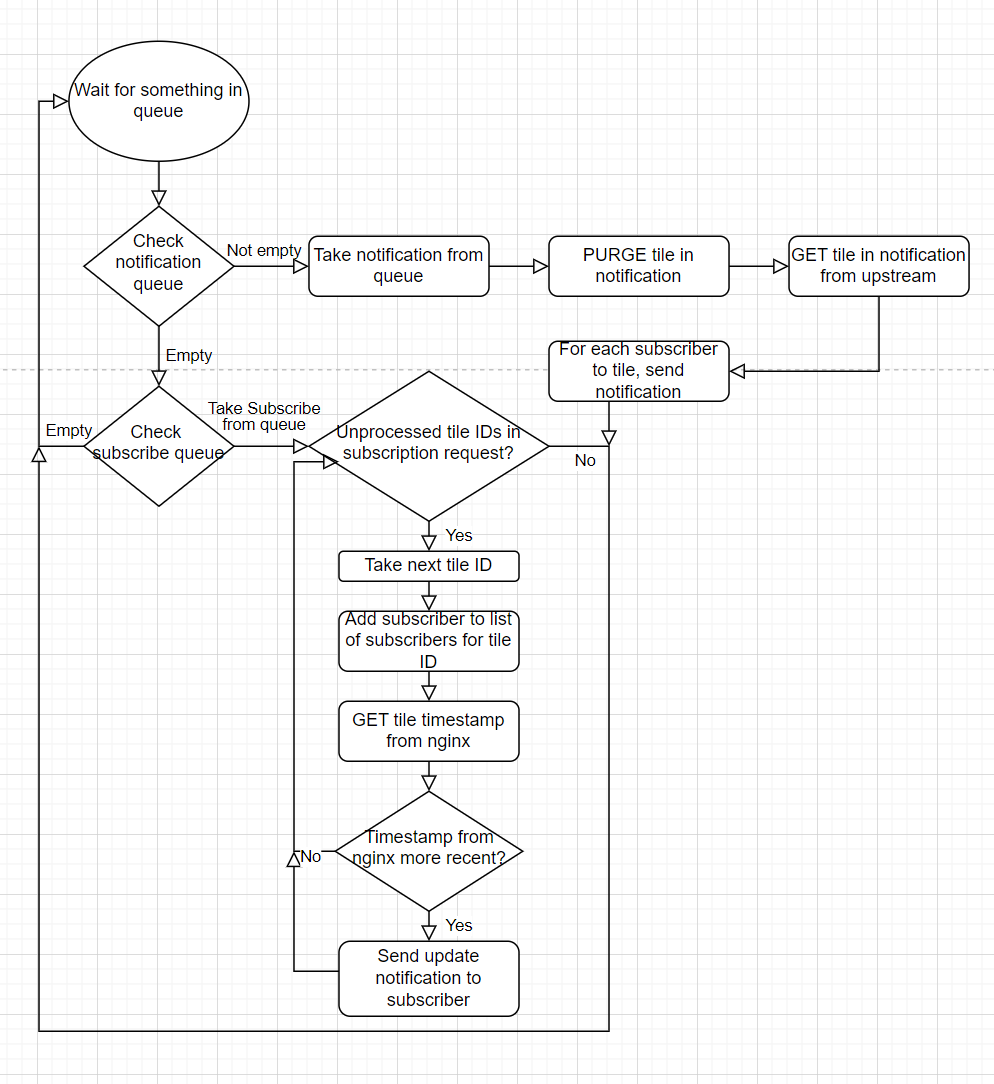
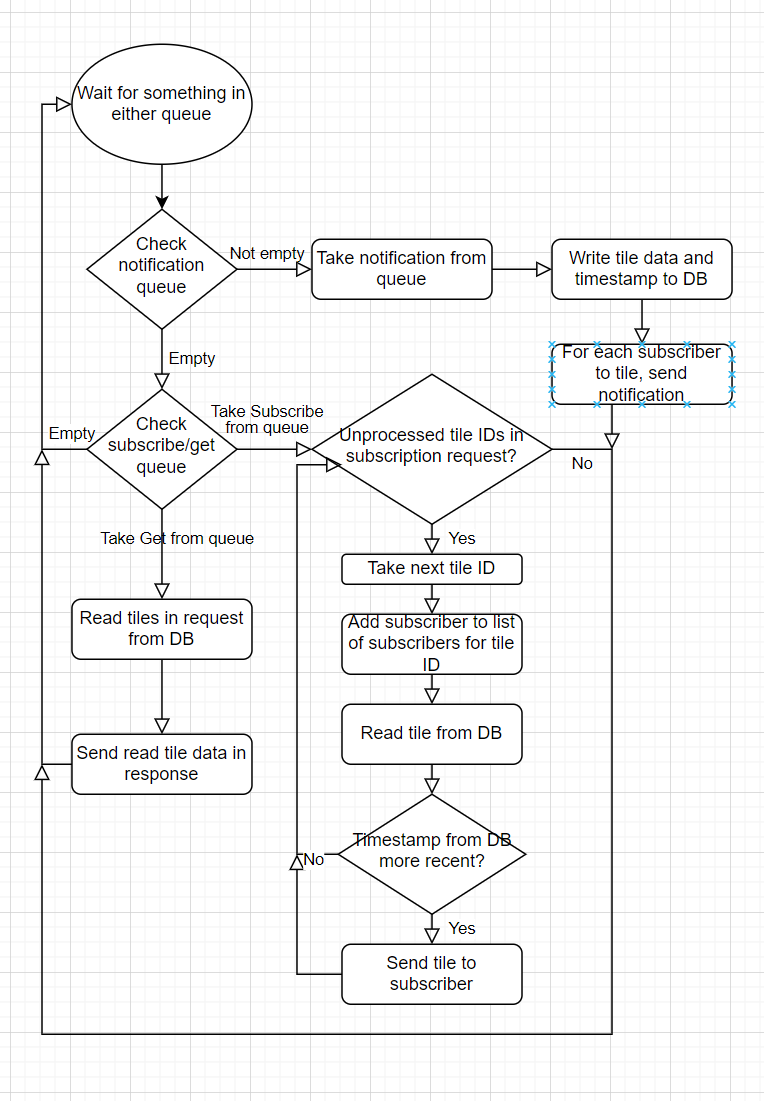
Diagrams of concurrent GETs and cache writes, and concurrent subsciption requests and cache writes for Nginx with sidecar option and local DB option
Nginx with sidecar concurrent gets and writes
Local DB concurrent gets and writes
Nginx with sidecar concurrent subscribes and writes
Local DB concurrent subscribes and writes
Workflow diagrams for Nginx with sidecar option and local DB option
Nginx with sidecar
Local DB
Open questions
Will we ever need to change which upstream node we’re connected to?
There might be a reason to do this, for instance if a drone is flying from one hub to another, and the hubs have different upstream nodes. However, we don’t think the design or use case is clear enough to implement with this in mind right now.
Alternatives considered
Offset instead of timestamp
It would be possible to just use a monotonically incrementing value instead of a timestamp to allow us to compare recency of tile data. This may save a small amount of space. However, a timestamp enables useful diagnostic information about the latency of the geodata pipeline, so it was judged more useful. Importantly, the timestamp must be set at or as near as possible to the source of a tile update (i.e. as far upstream as possible) in order for this latency information to be most useful.
Regions for subscription requests
It was considered to use regions instead of individual tiles when subscribing to tile updates. There was some concern that requests to subscribe to many tiles at once may create an overly large request. However, when looking at a request that encompasses an entire hub (a circle with a 10 mile radius) it was determined that this would only require around 50 tiles for tiles with a resolution of 256 * 256 pixels, and the request size would likely be in the 10s of kilobytes, which is not too large. See the math below.
Tiles per hub
10 miles ~= 16000 meters
Area of a hub: $16000 m * 16000 m * \pi \approx 800000000 m^2$
Area of a pixel: $16 m * 16 m = 256 m^2$
Area of a tile: $256 m^2 * 256^2 = 256^3 m^2$
$800000000 / 256^3 m^2 \approx 48$
~48 tiles per hub
Size of request for all tiles in hub
A hub’s area can be covered by about 48 tiles, but we might want separate tiles for different categories, e.g. terrain, airspaces, ELZs, etc. There might be around 5 categories. So the TileSubscriptionRequest for a hub might contain $48 * 5 = 240$ TimestampedTileIDs, which each contain one 8 byte timestamp, three 4 byte ints, and a string which we will assume doesn’t take up more than 20 bytes. $240 * (8 + (3 * 4) + 20) = 9600$, so a TileSubscriptionRequest for a hub shouldn’t require much more than 10 kb. We could reduce this somewhat if necessary by optimizing the category string, since we shouldn’t need to send that for every single tile when there are only a small number of possible categories.
Estimated sizes of some responses
Terrain
- A tile is $256 * 256 = 2^{16}$ pixels. For terrain, we can use a two-byte signed int, so a terrain tile response might be around $2^{16} * 2$ bytes, or 131 kB.
- An entire hub (about 48 tiles) would be around 6.3 MB.
Airspaces
- Airspace tiles are vector tiles which take a couple kB each. An entire hub might take up around 100 kB.
All data
- There will be other types of data which are required, such as speed limits and pedestrian activity. We won’t try to estimate them all, but if we assume they won’t require more space on average than 4 bytes per pixel, and assume that we could have around ten different types of data, we get ~2.6 MB per tile as the sum of all types, and ~126 MB per hub for all of the required data. This is a very rough estimate.