C2 Performance Tracking RTT Part
Originally
ADR--0123-C2 Performance Tracking - RTT Part (v18) · Source on Confluence ↗Title
| Traceability Links | |
|---|---|
| Jama Requirements | UERQ-HLR-1052 |
| Jira Tasks |
Context
FAA obliges us and other §44807 holders to keep track of the C2 link performance on a ongoing basis, specifically (from DroneUp’s Exemption):

And even more specifically, among other things like aircraft position, velocity, C2 link loss, ACJA-WT#2 asks that we measure

With some doubt we think they only mean network delay and not processing delay Uncrew introduces. This ADR predominantly propose how to measure and log RTT, but we admit that processing delay will be operationally very useful for us.
We propose to measure:
- Time it takes for a pilot (or platform) command to reach the onboard system
- Time it takes for an oboard alert or telemetry sample to reach the pilot.
Measuring how much time it takes for (say) the pilot pressing “Hold” and then flight controller receiving Hold is very difficult, because there is no one clock, with which one can measure the departure of the command from the pilot’s computer and its arrival onboard.
NTP
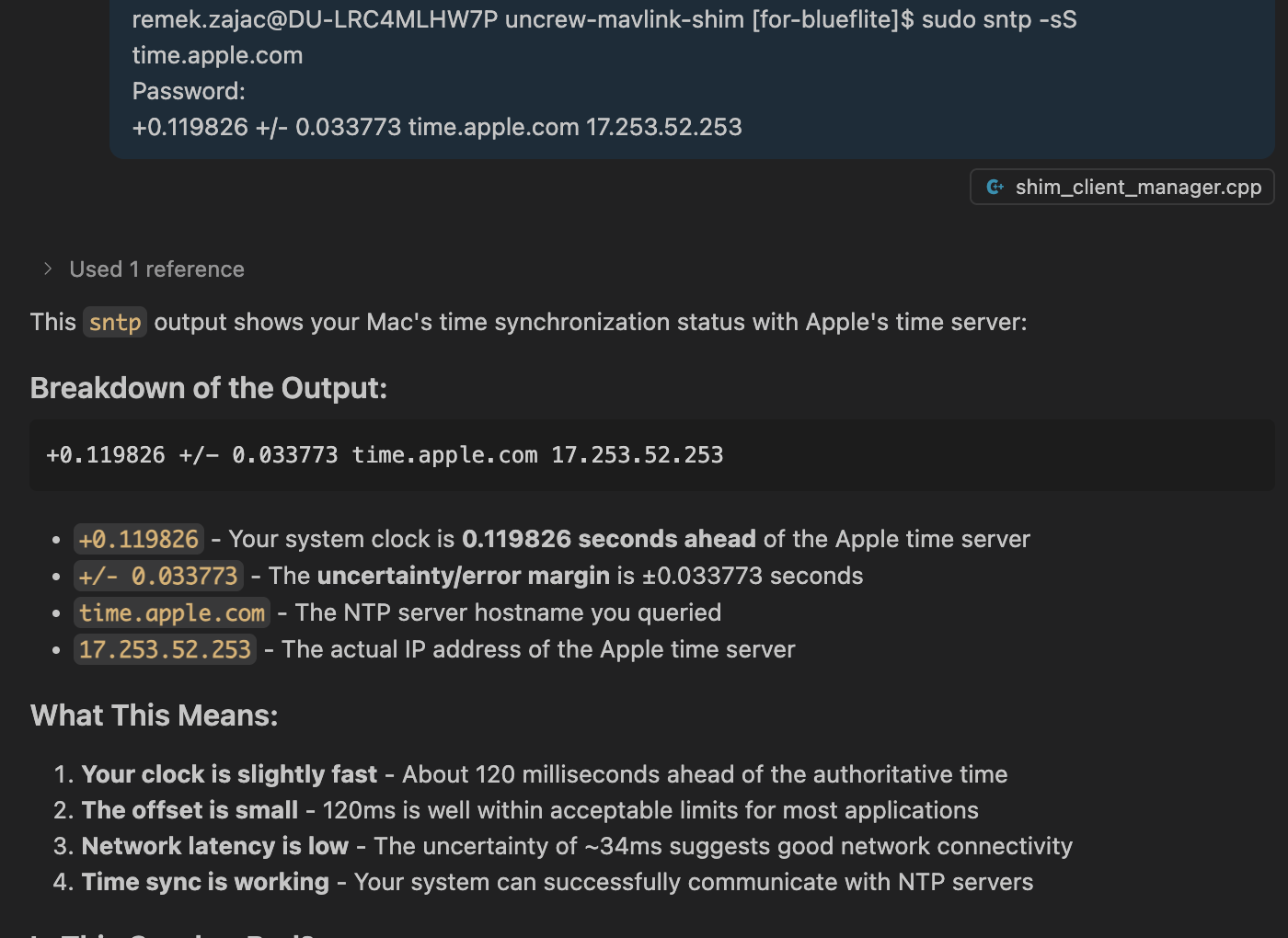
An NTP client is present on a typical desktop computer. This synchronizes the local system clock with an upstream reference. On the Mac computer I am typing this on, I see 120ms offset.
Mobile devices typically use NITZ to achieve the same goal

Ubuntu is likely to run on a drone compute, but the accuracy of the NTP synchronization is affected by the very thing we need to measure: network latency.
In networking, the duration it takes for a signal (packet/command) to propagate from one system to another is called End-to-End Delay or Latency. Because of the aforementioned problem, the End-to-End Delay is often approximated as half of the Round Trip Time (RTT).
RTT
In Uncrew there are two conceivable ways of measuring RTT:
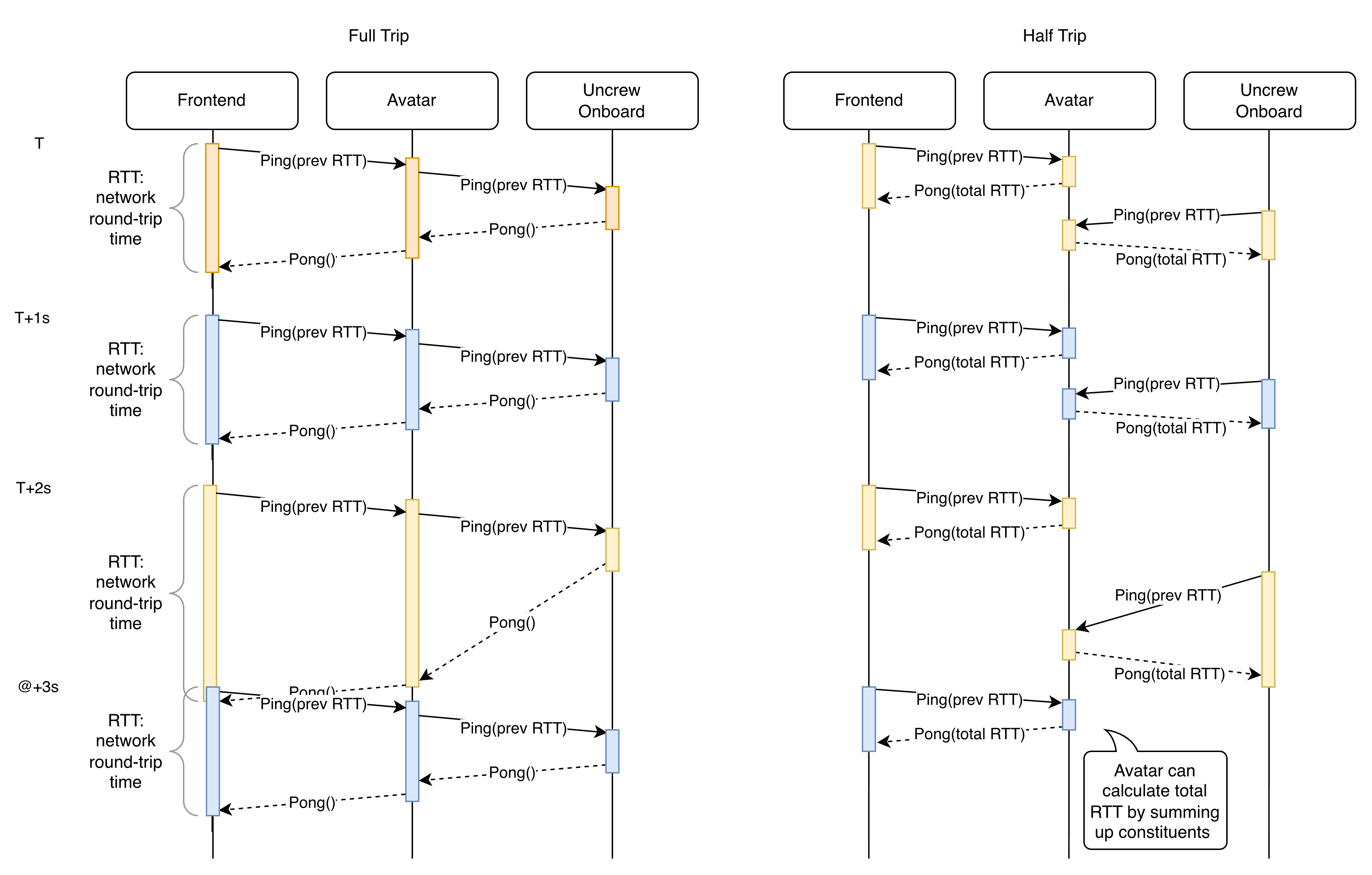
It is important for all participants: frontend, onboard and Avatar to be in agreement on what the current RTT and thus End-to-End delay is. Frontend to warn the pilot about deteriorating C2 link, Onboard to detect or anticipate C2 loss, inform coping strategies or shape outgoing traffic (limit the scope of frequency of outgoing telemetry). Both approaches achieve the same, but participants are informed with different delays.
- Full trip prioritizes the frontend - it is the first know the most up-to-date measure of RTT, Avatar gets to know it second and onboard third (delay: measurement frequency + RTT/2).
- Half-trip prioritizes the Avatar, Onboard and Frontend get their updates with similar delay of measurement frequency + RTT/4.
Pilot->Onboard
When it comes to measuring command latency, things become more difficult as we have to account for the processing delay (how much time it takes to plan a mission) and not just network delay.
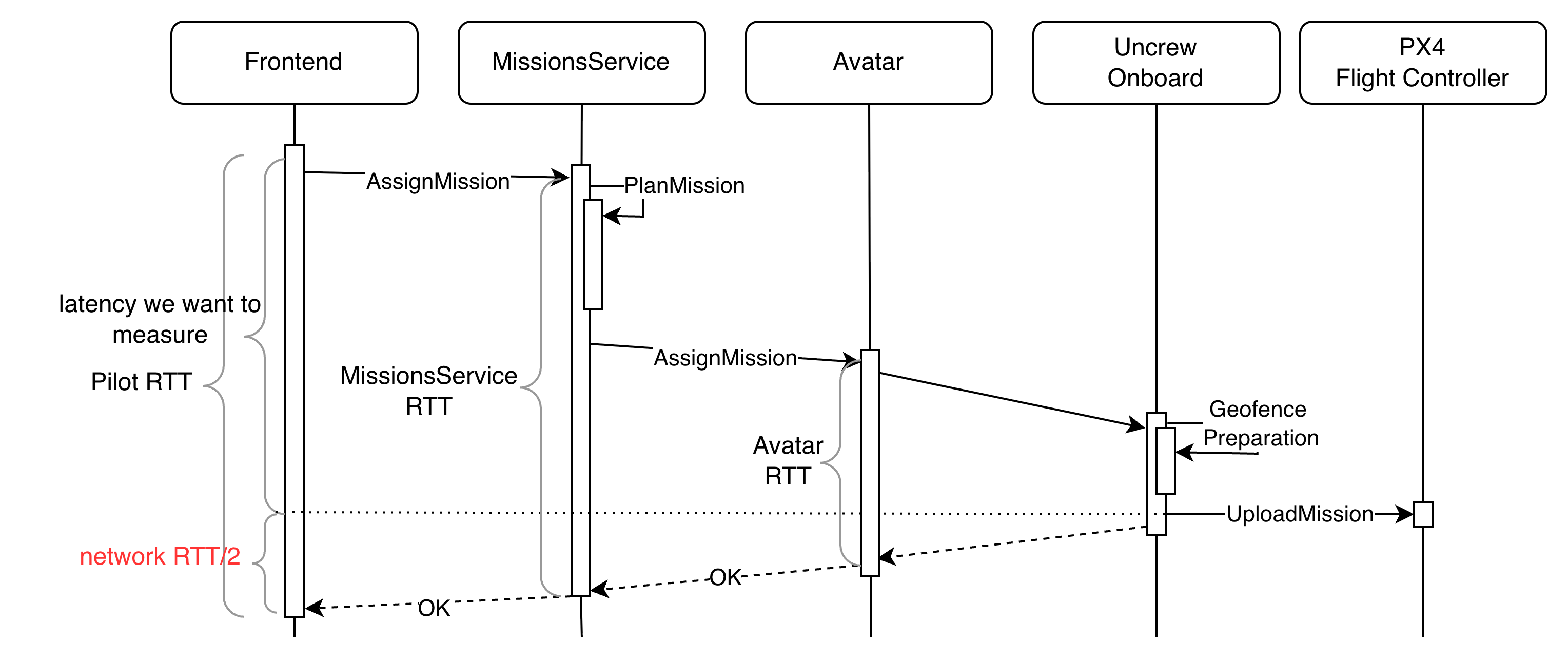
So it seems if we continue to measure network RTT and that comms between Uncrew Onboard and PX4 takes zero time, we can subtract half of network RTT from the time it takes to assign the mission and produce a decent approximation for how much time passes between the supervisor pressing “Assign Mission” button and that command reaching the PX4 flight controller.
It is unlikely, but plausible that the some services in the middle will want to perform additional processing/bookkeeping on the response (dotted) path - additional latency we want to discard.
Also there are MissionsService, Avatar and even Uncrew Onboard RTT that we may want to capture. We do in fact. With OTEL depositing the measurements to GCP logs and Honeycomb.
Onboard->Pilot
We could hastily try to reverse the Pilot->Onboard diagram, but:
Unlike StartMission, telemetry is a notification and not a command/request, which means the onboard system currently has no business nor method to wait for the result.
RTT is perfectly symmetric so why measure it from both sides? Yet, it’s not the network latency we’re solely interested in. It’s the time between the drone changing its position and rendering this change before the pilot’s eyes.
- The onboard system throttles outgoing telemetry (to 1Hz at the time of writing this, which introduces 1s delay in communicating the drone’s changing position).
- The frontend updates the map and drone icons on it with a tick frequency to avoid redrawing the map too often. This is especially important when displaying multiple drones. This introduces additional delay.
In other words, even if we bother to have the onboard system measure RTT for a telemetry update, this measure is likely to miss 2s delay introduced by the throttling and map refresh frequency. Both are static configurations that are arguably pointless to measure.
Logging Method
We today use Pendo to log all things frontend. Our logs are disjoint, some in Flight Log, some in Pendo, some in Honeycomb/GCP and some in ulog. This is a problem we acknowledge, but it’s a problem out of scope of this ADR.
In whatever way we solve this problem and whatever becomes of the Flight Log, this ADR assumes that Flight Log (owing to its durability and analytic-purpose format and medium) is the best recipient of the RTT and processing time recipient.
Decision
Network RTT
We shall measure RTT using the Half-Trip approach at a globally configurable frequency (probably 1Hz) and have Avatar log each measure in the Flight Log just like any other command or telemetry sample.
Processing Delay - Pilot->Onboard
We already log every span of remote interest with OTEL and to GCP logs/Honeycomb. We log it where it cannot be reached by our analytics platform or cross referenced with FlightLog. This is a larger problem to be solved by CORE-2291.
Processing Delay - Onboard->Pilot
We shall not measure the overall delay for telemetry and alerts reaching the pilot.
Consequences
The change is isolated from the rest of the function so its impact seems negligible.
Alternatives Considered
Considered having dedicated logs for the processing delay, but realized this is short-sighted and likely moving in the wrong direction relative to where CORE-2291 is expected to point.
Formal Impact
List any systems or services that are impacted by this architectural decision.