Integration Of Operational Databases To Data Lake
Originally
ADR--0136-Integration of Operational Databases to Data Lake (v39) · Source on Confluence ↗Metadata
| Field | Value |
| Status | Approved with Conditions [ARB Decision Record: ADR: BigQuery Federated Query Approach for UTM Analytics](confluence-title:///ARB Decision Record: ADR: BigQuery Federated Query Approach for UTM Analytics) |
| Date | 2026-02-12 |
| Decision Makers | Engineering Team |
| Reviewers | Engineering Team, Compliance Team |
| DAL | DAL-D Enhanced (Source System) |
| Supersedes | N/A |
Context and Problem Statement
The UTM platform manages operational (OLTP) data, including airspaces, flight plans, and operational intents within transactional GCP Cloud SQL databases. This data is currently siloed, preventing its use for critical regulatory reporting requirements.
The primary driver is ASTM F3548-21 SYS-910 (ACM0005), which mandates monthly aggregate operator conformance monitoring.
Failure to automate this data flow results in:
- Reliance on limited, incomplete APIs
- Frequent “break-glass” production database requests
- Inability to perform the complex, multi-source joins required for aviation safety analytics
We need a solution that enforces regulatory thresholds while protecting the safety-critical performance of the production environment.
Decision Drivers
| Driver | Description |
|---|---|
| Batch vs. Near Real-Time | Determine appropriate data freshness based on reporting cadence |
| Operational Complexity | Minimize maintenance burden on engineering teams |
| Security | Secure and Auditable connection to source database |
| Regulatory Compliance | Auditability for ASTM F3548-21 conformance monitoring (ACM) |
| Operational Risk Mitigation | Eliminate “break-glass” production DB access for ad-hoc reporting |
| Data Visibility | Comprehensive access to all required tables and fields |
| Data Governance | Adherence to ASTM F3548-21 SYS-910 (GEN0200) and organization data retention requirements |
| Production Stability | Minimal performance impact on DAL-D Enhanced production database |
Decision Outcome
Considered Options
Option 1: No Data Movement - BigQuery Federated Queries (External Connection) - Choosen
Enabling query source data directly from BigQuery without physically moving or duplicating data.
Pros
- Zero Data Latency - Queries reflect the current state of Cloud SQL in real-time—no synchronization delays or stale data concerns. Analysts always work with the most up-to-date information.
- No Storage Duplication - Eliminates the need to replicate and store data in BigQuery, reducing storage costs and avoiding data drift between source and analytical environments.
- Data Governance - Limits the data retention requirements to Cloud SQL.
- Simplified Architecture - No ETL pipelines to build, maintain, monitor, or troubleshoot. Reduces operational burden and accelerates time-to-insight for analysts.
- Reduced Development Effort - No DAG development, schema mapping, or incremental load logic required. Analysts can begin querying immediately once the external connection is established.
- Single Source of Truth - Data is never duplicated, eliminating reconciliation issues and ensuring consistency between operational and analytical views.
- Flexible Query Patterns - Supports ad-hoc exploratory analysis without pre-defining extraction scope. Analysts can access any table or column as business questions evolve.
- Lower Total Cost of Ownership - No Cloud Composer compute costs for extraction jobs, no BigQuery storage costs for replicated data, and minimal engineering maintenance overhead.
- Security - No need to save DB credentials, instead we create a BigQuery connection, which creates a service agent, providing Cloud SQL access to this service agent and sharing this agent to end users ensure highest security. Since its managed service, it takes care of secure networking. By configuring connection timeout, statement timeout, worker memory etc to safe guard the database against the resource consumption issues.
Cons
- Source DB Load - Schedule heavy analytical workloads during off-peak hours; implement query complexity guidelines for analysts
- Data Governance - Need to monitor the queries ran by the external connections.
- Limitation - There are known limitations with this approach
- Though there is no data copy, BQ can maintain the transformed copy of cloud sql data.

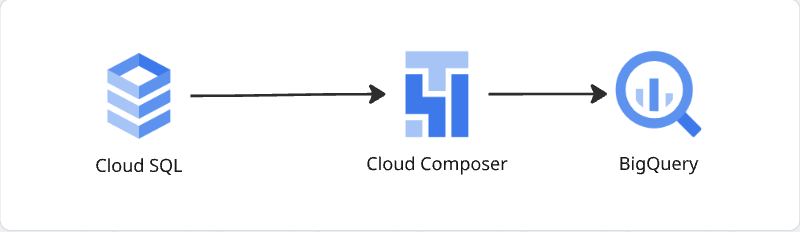
Option 2: Scheduled Batching using Cloud Composer
GCP Cloud Composer, a fully managed Apache Airflow based workflow orchestration service, allows to batch load Cloud SQL to BigQuery.
Pros
- Low Operational Complexity - Data team already has production ready Cloud Composer Environment.
- BigQuery Compute Power - As data presents in Big Query, we can leverage on BigQuery’s massively parallel, serverless architecture to do complex analytical work, without strain Cloud SQL.
- Governance & Data Quality Gates - Pipeline orchestration enables enforcement of data quality checks, PII masking, schema validation, and access controls before data reaches analysts. Ensures compliance and data integrity at every stage.
- Cost Effective at Scale - BigQuery’s storage costs are minimal compared to compute-heavy alternatives. Batch processing is significantly more cost-efficient than streaming for current data volumes and refresh requirements.
Cons
- Introduces schema coupling - changes to source schema require corresponding DAG updates.
- Requires monitoring to prevent query overlap with peak operational hours
- Upstream Database Support - Upstream Databases should support incremental data loading by providing information on what got changes during the batch executions.
- Data Staleness - Because Composer is batch-based, data in BigQuery is only as fresh as the last successful DAG run.
When using Cloud Composer to move data to BigQuery, we can choose between a Direct DB approach and a API based approach.
| Feature | Direct Database Access (Chosen) | App-Level API Access (Rejected) | Comments |
| Visibility | Full / Limited: Access to all tables and columns, including new schema changes. | Limited: Only exposes data defined by developers; often has significant “visibility gaps”. | In both the approaches changes are inevitable, but depends on how we handle the change. If we have full access visibility is full, when we limit it using the GRANT or DENY, we need to ensure newly created ones are listed there. |
| Performance | High: Fastest retrieval for bulk data moves. Utilizes read-replicas to protect production. | Low/Risky: High risk of memory failures or timeouts during large data transfers. | We encounter this problem during the first time data sync, sub sequent loads will be delta loads which are very small considering the current volume. |
| Governance | Direct: Governance shifts to the Data Team; managed via SQL roles and views. | Indirect: Managed by the application team; provides a secure abstraction layer. | Application team can limit the access to specific tables, column or rows when providing DB credentials or can create a new reporting/ analytical schema with the limited set of database objects. |
| Complexity | High Maintenance: Requires updating schema mapping CCIs for every DDL change. | High Development: Requires building and maintaining endpoints for every new data requirement. | Schema changes can be detected and non breaking schema chnages can be handled efficiently, breaking schema changes requires prior notification. |
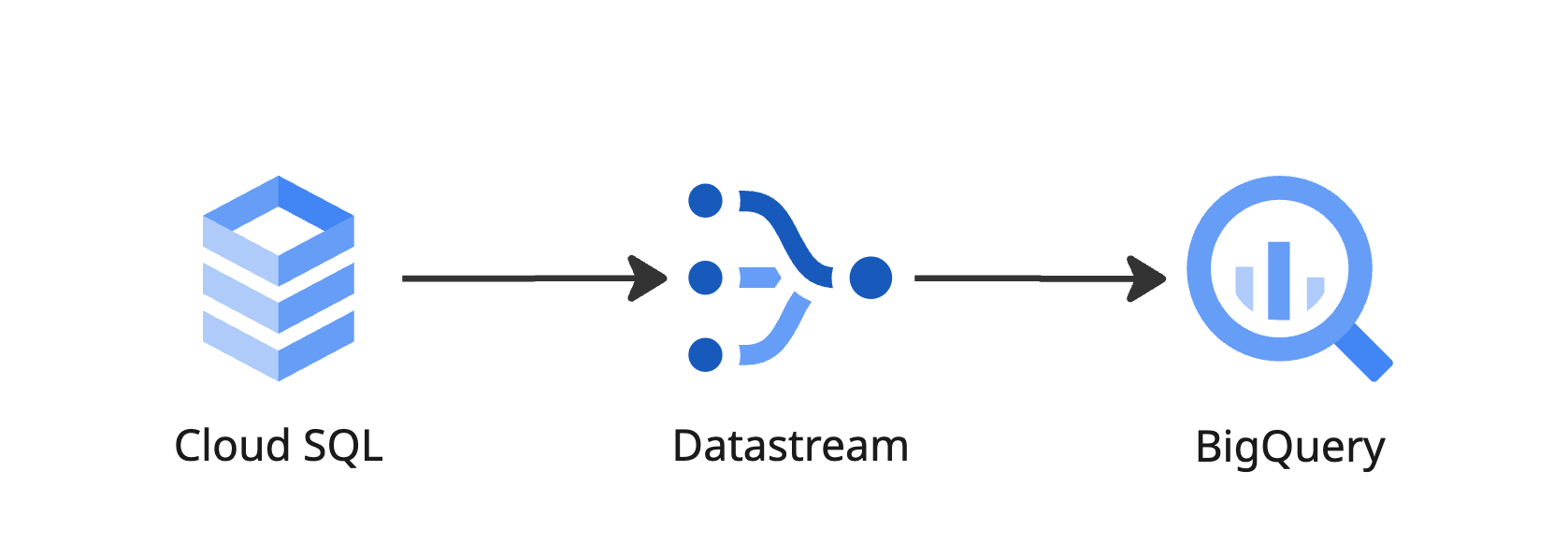
Option 3: Streaming Data from UTM Cloud SQL to BigQuery
Options Considered
- GCP Datastream – GCP managed change data capture (CDC) service, which is scalable, managed and handles schema changes (non breaking)
- GCP Dataflow - GCP managed Unified bath and stream processing services, Full transformation control, handles business logic
- GCP Dataproc - GCP managed Cluster for Data Processing (Apache Flink)
- Open-source CDC – Debezium with Kafka-based implementation for change data capture
Given the lack of compelling use cases requiring streaming data, the operational burden, and the disproportionate costs relative to business value, batch-based data replication remains the preferred approach. This decision should be revisited if:
- Near-real-time analytics requirements emerge
- Data freshness SLAs tighten to sub-hourly thresholds
- Downstream systems require event-driven data availability
Safety Impact
- Safety-Critical Data Flow: No. Ingestion is strictly one-way (Production → Lake).
- Operational Risk: High. Direct Primary DB access could cause resource exhaustion. Mitigated by strict off-peak scheduling and CCI-controlled throttled queries.
- Fault Tolerance: Ingestion failure delays reporting but does not compromise active flight safety.
Assumptions & Constraints
- UTM Currently has airspace data, this can be better loaded to Data Lake by subscribing to Atlas Pipelines.
- If UTM data grows Storing all historic data is Big Query is not required, Data will be moved to tiered storage.
- Assumption: The Data Team will maintain SQL views that mirror application-level governance and FAA requirements.
- Constraint [Operational]: No batch jobs or heavy analytical extractions are permitted during known high-density flight windows to protect the Primary DB.
- Constraint [Technical]: Direct database access is limited to read-only permissions; no DML (Data Manipulation) or DDL (Data Definition) operations are permitted on the source Production DB.
Related Requirements
- ASTM F3548-21 SYS-910: Mandatory Conformance Monitoring (ACM0005).
- ASTM F3548-21 GEN0200: 1080-hour retention limit for external data.
- FAA NTAP / USP Agreement Section 5(a): 45-day minimum retention for cross-provider data.
Implications
PE Action: Provision required IAM permissions and set up database performance alerts.
If a new DB credentail is generated, it should be created with
- connection timeout, statement timeout, worker memory etc to safe guard the database against the resource consumption issues.
Technical Debt: A follow-on ADR is required to evaluate
- either stream loading or batch loading data, based on the additional reporting requirements
- adding a Read Replica as flight volume scales.
Monitoring: Establish “Freshness Alerts” for regulatory reporting timelines.
Release Gate: App and Data teams must implement a Synchronized Release Gate for all schema changes.