Centralized Notification Service Architecture
Originally
ADR--0138--Centralized Notification Service Architecture (v6) · Source on Confluence ↗Centralized Notification Service Architecture
Metadata
| Field | Value |
|---|---|
| Status | Draft |
| Date | 2026-02-23 |
| Decision Makers | Engineering Team, Architecture Team |
| Reviewers | TBD |
| DAL | DAL-D Enhanced |
| Supersedes | N/A |
| Superseded by | N/A |
Context and Problem Statement
The Uncrew platform comprises multiple backend services — UTM (Themis gRPC, Themis API, Themis Charger), Mission Service, UAV telemetry — each of which generates events that operators and stakeholders need to know about in near-real-time. Today, there is no unified notification mechanism. Each service either lacks user-facing notifications entirely or implements ad-hoc, service-specific alerting (e.g., labels, manual Slack messages). This means operators can miss critical events such as airspace conflicts, mission state changes, geofence breaches, or delivery status updates.
Scope: human consumers only. This ADR addresses the problem of notifying *people* — operators, managers, on-call engineers — about platform events and active conditions. It does not address service-to-service event routing or automated machine-initiated responses to conditions (e.g., a service automatically aborting a mission in response to a geofence breach alert). The notification service’s consumers are humans and the UIs/channels through which humans receive information. If the platform later requires automated responses triggered by the same events that produce notifications or alerts, that capability will need its own architecture — likely an event bus or rule engine — and this ADR will need to be revisited.
As the platform scales — more concurrent flights, more operators, more integration partners — the absence of a centralized notification service creates several compounding problems:
- Operator awareness gaps: Critical events (e.g., operational intent conflicts from UTM, mission failures, UAV anomalies) are not surfaced to operators in a timely or consistent manner.
- No notification history: There is no persistent record of what notifications were sent, when, or whether they were acknowledged — making incident review and compliance auditing difficult.
- Duplicated effort: If each service implements its own notification delivery (email, Slack, UI push), the team multiplies integration work and inconsistency across services.
- Multi-channel delivery: Stakeholders need notifications via different channels depending on urgency and role — real-time web push for operators, email digests for managers, Slack alerts for on-call engineers.
Decision Drivers
- Real-time delivery to the Uncrew UI — Operators must receive critical notifications (airspace conflicts, mission failures) within seconds via the web application.
- Multi-channel support — The system must support at least web push, email, and Slack, with an extensible architecture for future channels (SMS, PagerDuty, mobile push).
- Persistent notification storage — All notifications must be stored with delivery status and acknowledgment tracking for audit and compliance.
- Simple producer integration — Producing services (UTM, Mission, UAV) should submit notifications via a well-defined API without knowledge of routing or delivery channels.
- Scalability — The service must handle bursty notification loads (e.g., multiple simultaneous airspace conflicts) without dropping or delaying critical alerts.
- Consistency with platform tech stack — The solution should align with the existing Go, gRPC, and PostgreSQL stack used across Uncrew services.
- Extensible notification preferences — Users should be able to configure which notification types they receive and via which channels.
- Client-side subscription filtering — UI clients must be able to subscribe to a filtered stream of notifications (e.g., by mission ID, site ID, event type) so they only receive what is relevant to their current operational context.
- Transient alert lifecycle — The system must support alerts that represent active conditions (e.g., UA low battery, GPS degradation, high wind) which are raised by producers and automatically cleared when the condition resolves — distinct from persistent notifications that record discrete events.
Considered Options
Option 1: Centralized Notification Service with gRPC API Ingestion
Description: Build a dedicated Go microservice that exposes a gRPC API for upstream services to submit notifications. The service applies routing/filtering logic based on user preferences, persists all notifications to PostgreSQL, and delivers them through pluggable channel adapters (gRPC/WebGRPC for UI, SMTP for email, Slack webhook, etc.). Producers call the Notification Service directly via gRPC — the same communication pattern already used for all service-to-service calls in the platform.
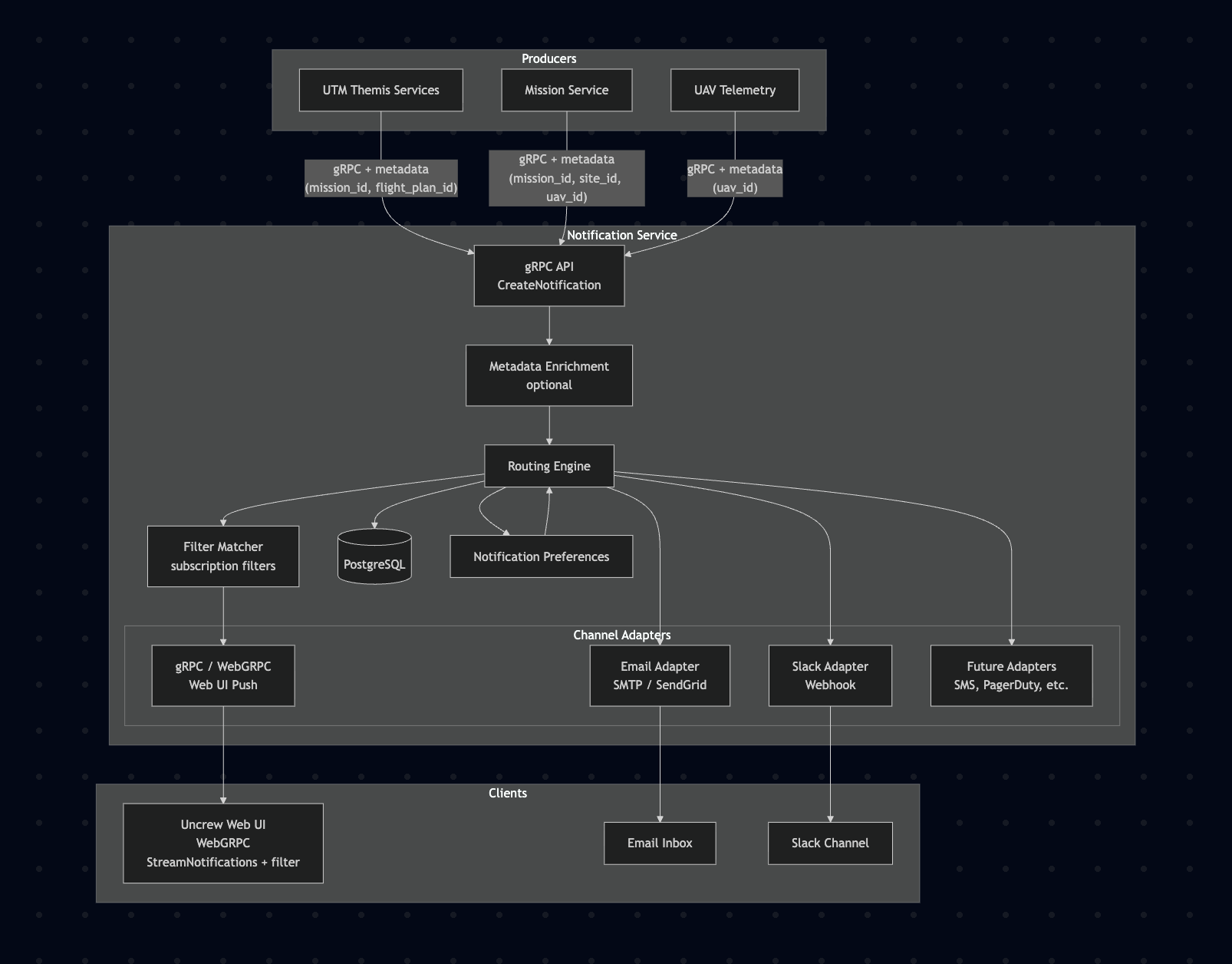
Mermaid diagram
graph TB
subgraph Producers
UTM[UTM Themis Services]
MS[Mission Service]
UAV[UAV Telemetry]
end
subgraph "Notification Service"
API[gRPC API<br/>CreateNotification]
ENR[Metadata Enrichment<br/>optional]
RE[Routing Engine]
FM[Filter Matcher<br/>subscription filters]
PS[(PostgreSQL)]
NP[Notification Preferences]
subgraph "Channel Adapters"
WG[gRPC / WebGRPC<br/>Web UI Push]
EM[Email Adapter<br/>SMTP / SendGrid]
SL[Slack Adapter<br/>Webhook]
FUT[Future Adapters<br/>SMS, PagerDuty, etc.]
end
end
UTM -->|"gRPC + metadata<br/>(mission_id, flight_plan_id)"| API
MS -->|"gRPC + metadata<br/>(mission_id, site_id, uav_id)"| API
UAV -->|"gRPC + metadata<br/>(uav_id)"| API
API --> ENR --> RE
RE --> PS
RE --> NP
NP --> RE
RE --> FM
FM --> WG
RE --> EM
RE --> SL
RE --> FUT
subgraph Clients
UI[Uncrew Web UI<br/>WebGRPC<br/>StreamNotifications + filter]
MAIL[Email Inbox]
SLACK[Slack Channel]
end
WG --> UI
EM --> MAIL
SL --> SLACK
Pros:
- Full control over notification lifecycle (create, deliver, acknowledge, expire)
- Persistent storage enables audit trail, replay, and debugging
- Single gRPC API for both producers (CreateNotification) and consumers (ListNotifications, StreamNotifications) — one service, one contract
- Producers integrate via the same gRPC pattern already used for all service-to-service calls — no new infrastructure to learn
- Synchronous acknowledgment — producers get immediate confirmation that the notification was accepted and persisted
- WebGRPC (gRPC-Web) for browser clients — consistent with platform UI patterns
- Channel adapters are independently deployable and testable
- User preference engine allows fine-grained notification routing
- No dependency on GCP PubSub — simpler infrastructure footprint
Cons:
- Requires building and maintaining a new microservice
- Routing engine and preference management add complexity
- Producers have a runtime dependency on the notification service — if it’s down, notification submission fails (mitigated by retries and circuit breakers on the producer side)
- Operational overhead of another service to deploy, monitor, and scale
Estimated effort: Low
Option 2: Extend Each Service with Built-in Notification Capabilities
Description: Each producing service (UTM, Mission Service, UAV) implements its own notification delivery logic — directly sending emails, posting to Slack, and pushing to the UI via its own gRPC streams.
Pros:
- No new service to deploy — notifications are co-located with business logic
- Each team owns their notification behavior end-to-end
- Potentially faster initial delivery for a single service
Cons:
- Duplicated notification infrastructure across every service (email clients, Slack webhooks, UI push)
- No unified notification history or audit trail
- User preference management must be replicated in each service
- Inconsistent notification format and behavior across services
- O(n) integration cost — each new channel must be added to every service
- Violates single-responsibility principle; complicates each service’s codebase
- No cross-service notification aggregation or deduplication
Estimated effort: Small per service initially, but Large in aggregate
Option 3: Third-Party Notification Platform (e.g., Novu, Knock, OneSignal)
Description: Adopt a third-party notification infrastructure platform that provides multi-channel delivery, user preferences, and notification history out of the box. Upstream services call the platform’s API to trigger notifications.
Pros:
- Rapid time-to-value — multi-channel delivery, preference management, and UI components included
- Battle-tested delivery infrastructure (retries, rate limiting, batching)
- Reduces custom code for channel integrations
- Some platforms offer self-hosted options
Cons:
- External dependency for a critical operational path — risk of vendor lock-in
- May not support gRPC/WebGRPC natively — requires REST adapter or custom integration for the Uncrew UI pattern
- Cost scales with notification volume, potentially significant at operational scale
- Limited control over notification storage location — may conflict with data residency or compliance requirements
- Customization of routing logic may hit platform limitations
- Additional latency from external API calls for real-time notifications
- Team must learn and maintain integration with a third-party system rather than platform-native patterns
Estimated effort: Small for initial integration, but ongoing vendor management and potential migration cost
Option 4: Do Nothing
Description: Continue without a centralized notification system. Rely on existing logging, dashboards, and manual monitoring.
Pros:
- Zero implementation cost
- No new infrastructure to maintain
Cons:
- Operators continue to miss critical events
- No audit trail for notifications
- Does not scale with increasing flight operations
- Incident response remains reactive rather than proactive
- Fails to meet operational requirements for 2026 scaling targets
Estimated effort: None
Decision Outcome
Chosen option: “Option 1: Centralized Notification Service with gRPC API Ingestion”
We will build a dedicated notification microservice in Go that exposes a gRPC API for upstream services to submit notifications.
The service persists notifications to PostgreSQL and delivers them through pluggable channel adapters. The same gRPC API serves both producers (CreateNotification, RaiseAlert,ClearAlert) and consumers (ListNotifications, StreamNotifications,ListActiveAlerts,StreamAlerts, AcknowledgeNotification), while a WebGRPC (gRPC-Web) endpoint serves the Uncrew web UI. In addition to persistent notifications (discrete events), the service supports **alerts** — transient conditions that are raised when a condition arises and cleared when it resolves, without requiring operator action. This enables UA telemetry systems to surface active conditions (low battery, GPS degradation, communication link warnings) through the same centralized service, giving operators real-time situational awareness of both events and active states. This approach gives us full control over the notification and alert lifecycle, a persistent audit trail, and an extensible architecture for adding new delivery channels — all using the standard gRPC patterns already established across the platform.
Reversibility: Moderately costly to reverse — producers and the UI integrate directly with the notification service gRPC API. However, the API contract is defined via .proto files, so the service implementation can be replaced (e.g., swapped for a managed platform) without changing the producer integration as long as the proto contract is honored.
Argument
Alignment with decision drivers:
The centralized service directly addresses all eight decision drivers. Real-time delivery to the UI is achieved via gRPC streaming (server-side streaming or bidirectional) exposed through WebGRPC for browser clients — this is the same pattern already used by other Uncrew services and avoids introducing WebSockets or a separate push infrastructure. Multi-channel support is handled by pluggable channel adapters, each independently developed and deployed, so adding email today and Slack tomorrow doesn’t require changes to the core routing engine. PostgreSQL persistence gives us a full notification history with delivery status, acknowledgment timestamps, and read/unread state — essential for compliance auditing and incident review.
Producers submit notifications by calling the service’s CreateNotification gRPC endpoint — the same service-to-service communication pattern used throughout the platform. This means no new infrastructure (e.g., PubSub topics) needs to be provisioned or maintained, and producers get a synchronous response confirming the notification was accepted and persisted. The gRPC contract is defined in .proto files, giving producers a strongly-typed, versioned API with clear error semantics.
Why not Option 2 (per-service notifications)?
Distributing notification logic across each service appears simpler initially but creates compounding technical debt. With 6+ services already in the platform and more planned, every new delivery channel (email, Slack, SMS) must be integrated N times. User preferences would need to be stored and queried by each service independently, leading to inconsistent behavior. There is no single place to query “show me all notifications for operator X across all services” — a critical requirement for the Uncrew UI dashboard. The aggregate effort far exceeds building a centralized service, and the maintenance burden grows linearly with both services and channels.
Why not Option 3 (third-party platform)?
Third-party notification platforms like Novu or Knock offer compelling out-of-the-box functionality. However, the Uncrew platform is standardized on gRPC/WebGRPC for all service-to-service and service-to-UI communication. Most notification platforms are REST-first, which would require an adapter layer and introduce architectural inconsistency. Additionally, real-time notification delivery for safety-related events (airspace conflicts, mission failures) must have predictable, low latency — adding an external API hop introduces uncertainty. Data residency and the ability to fully audit the notification pipeline are also concerns that a self-managed service addresses more directly. The cost savings of a managed platform are offset by the integration friction and operational risk for a critical path.
Trade-offs accepted:
Building a custom notification service means we bear the full development and operational cost — building the routing engine, channel adapters, preference management, and idempotency logic. We also accept that producers have a runtime dependency on the notification service — if it’s unavailable, notification submission fails. This is mitigated by standard gRPC retry policies and circuit breakers on the producer side, and by the fact that notification failure does not block the producer’s primary business logic (fire-and-forget with retry). We also accept the operational burden of deploying and monitoring another microservice.
Idempotency strategy:
Producers include an idempotency key (source service + event ID) with each CreateNotification call. The notification service enforces uniqueness via a PostgreSQL unique constraint on this key. Duplicate submissions (e.g., from producer retries) return success without creating a duplicate notification. This is simpler than PubSub-based deduplication because the producer controls the idempotency key and gets a deterministic response.
Subscription filtering:
UI clients subscribe to real-time notifications via StreamNotifications, providing a filter that specifies which notifications they want to receive. Filters can include any combination of dimensions: mission_id, site_id, event_type, severity, source_service, etc. The notification service evaluates each persisted notification against all active subscriptions and delivers only to matching streams. This keeps bandwidth efficient — an operator monitoring a specific mission only receives notifications relevant to that mission, not the full platform-wide firehose.
Filters are matched against the metadata fields that producers attach to each notification (see Producer Metadata below). The filter supports both exact match (mission_id = "abc-123") and wildcard/absent fields (omitting site_id from the filter means “match any site”).
Producer metadata and partial knowledge:
Producers must attach structured metadata to each CreateNotification call to enable downstream filtering. The metadata is a well-known set of optional fields:
| Metadata Field | Type | Example Producers | Description |
|---|---|---|---|
mission_id | string | Mission Service, UTM Themis | The mission this notification relates to |
site_id | string | Mission Service | The operational site |
uav_id | string | UAV Telemetry, Mission Service | The specific UAV |
airspace_id | string | UTM Themis | The airspace volume |
flight_plan_id | string | UTM Themis | The flight plan |
operator_id | string | Mission Service | The assigned operator |
Critically, not every producer knows every field. For example, UTM Themis may know mission_id and flight_plan_id but does not know site_id. The notification service handles this with two mechanisms:
- Partial metadata is valid. Producers submit only the fields they know. The notification service stores whatever is provided. A filter that includes
site_idwill not match a notification that lackssite_idin its metadata — this is correct behavior, because the client has explicitly asked for site-scoped notifications. - Metadata enrichment (optional, Phase 2+). The notification service can optionally enrich incomplete metadata by resolving missing fields from a reference source. For example, given a
mission_id, the service could look up the associatedsite_idfrom the Mission Service (via a lightweight gRPC call or a local cache). This allows a UTM notification that only carriesmission_idto still match a UI subscription filtered bysite_id. Enrichment is performed asynchronously after persistence and before subscription matching, so it does not add latency to the producer’sCreateNotificationcall. Enrichment rules are configurable and can be added incrementally as cross-service relationships become clear.
Alerts: transient condition lifecycle
In addition to notifications (discrete events that record something that happened), the notification service supports alerts — active conditions that arise, persist while the condition holds, and then clear when the condition resolves. Alerts represent the real-time state of a transient condition, not a historical event. The key distinction:
| Aspect | Notification | Alert |
|---|---|---|
| Semantics | “Something happened” (event) | “Something is happening right now” (condition) |
| Lifecycle | Created → delivered → read → acknowledged | Raised → (optionally acknowledged) → cleared |
| Resolution | Resolved by user action (read/acknowledge) | Resolved by producer when condition clears — no user action required |
| Persistence after resolution | Remains in notification history permanently | Moves to cleared state; retained for audit but no longer active |
| UI treatment | Notification center / inbox | Active alert banner or indicator; disappears when cleared |
| Typical producers | Mission Service (mission completed, mission failed), UTM (airspace conflict detected) | UAV Telemetry (low battery, GPS degradation, high wind, comm link warning), Mission Service (geofence proximity) |
Why alerts belong in the notification service:
Alerts share the same infrastructure needs as notifications — real-time delivery to the UI via gRPC streaming, subscription filtering by metadata (especially uav_id and mission_id), multi-instance fan-out via PostgreSQL LISTEN/NOTIFY, and persistent storage for audit. Building a separate “alert service” would duplicate all of this infrastructure. The notification service already has the routing engine, channel adapters, and subscription management needed to deliver alerts to the right operators. The incremental cost of adding alert semantics (raise/clear lifecycle, active-state tracking) to the existing service is far lower than building a parallel system.
Alert API surface:
The notification service gRPC API adds the following RPCs for alert lifecycle management:
| RPC | Direction | Description |
|---|---|---|
RaiseAlert | Producer → Service | Raises a new alert or re-raises an existing alert (idempotent by alert_key). Includes severity, event type, metadata, and a human-readable message. |
ClearAlert | Producer → Service | Clears an active alert by alert_key. The alert transitions to cleared state with a cleared_at timestamp. If the alert is already cleared, the call is a no-op. |
ListActiveAlerts | Consumer → Service | Returns all currently active (non-cleared) alerts, optionally filtered by metadata fields (uav_id, mission_id, site_id, etc.). |
StreamAlerts | Consumer → Service | Server-side streaming RPC that pushes alert state changes (raised, updated, cleared) to connected UI clients. Supports the same subscription filter mechanism as StreamNotifications. |
AcknowledgeAlert | Consumer → Service | Marks an active alert as acknowledged by an operator — the alert remains active (the condition still holds) but the operator has seen it. Distinct from clearing. |
Alert keying and idempotency:
Each alert is uniquely identified by an alert_key — a composite of the source service, condition type, and the entity it applies to. For example:
uav_telemetry:low_battery:uav-007— low battery on UAV uav-007uav_telemetry:gps_degraded:uav-007— GPS signal degradation on UAV uav-007mission_service:geofence_proximity:m-42— mission m-42 approaching geofence boundaryuav_telemetry:comm_link_warning:uav-007— communication link quality warning on UAV uav-007
The alert_key serves as the idempotency key for RaiseAlert. If a producer calls RaiseAlert with an alert_key that already has an active alert, the service updates the existing alert’s last_raised_at timestamp and message (the condition is still active, possibly with updated severity or details) rather than creating a duplicate. This is essential for telemetry-driven alerts where the producer may re-send the alert condition on every telemetry cycle.
ClearAlert uses the same alert_key to identify which alert to clear. Producers call ClearAlert when the condition resolves (e.g., battery level recovers above threshold, GPS signal restores). If no active alert exists for the key, the call is a no-op — this makes ClearAlert safe to call unconditionally.
Alert lifecycle state machine:
RaiseAlert (new key)
│
▼
┌─────────┐
RaiseAlert ────►│ ACTIVE │◄──── RaiseAlert (same key: update timestamp + message)
(same key) └────┬────┘
│
┌──────────┼──────────┐
│ │ │
AcknowledgeAlert │ ClearAlert
│ │ │
▼ │ ▼
┌──────────┐ │ ┌─────────┐
│ ACTIVE + │ │ │ CLEARED │
│ ACKED │──────┘ └─────────┘
└──────────┘ ClearAlert- ACTIVE: The condition is present. The alert is visible to operators in the UI active alert panel.
- ACTIVE + ACKNOWLEDGED: The condition is still present, but an operator has acknowledged seeing it. Still visible, but visually distinguished (e.g., muted indicator).
- CLEARED: The condition has resolved. The alert is removed from the active alert panel. The record is retained in the database for audit (with
cleared_attimestamp andcleared_bysource).
UA alert examples:
| Alert Key Pattern | Event Type | Severity | Raised When | Cleared When | Example Message |
|---|---|---|---|---|---|
uav_telemetry:low_battery:<uav_id> | uav_low_battery | WARNING / CRITICAL | Battery below threshold (e.g., < 30% WARNING, < 15% CRITICAL) | Battery recovers above threshold or UAV lands | “UAV uav-007 battery at 22% — WARNING” |
uav_telemetry:gps_degraded:<uav_id> | uav_gps_degraded | WARNING | GPS accuracy degrades below acceptable limit | GPS accuracy restores | “UAV uav-007 GPS accuracy degraded (HDOP > 5.0)” |
uav_telemetry:comm_link_warning:<uav_id> | uav_comm_link_warning | WARNING / CRITICAL | Communication link quality drops below threshold | Link quality restores | “UAV uav-007 comm link signal weak (RSSI -85 dBm)” |
uav_telemetry:high_wind:<uav_id> | uav_high_wind | WARNING | Wind speed exceeds operational limit for UAV type | Wind speed drops below limit | “UAV uav-007 wind 28 kt — exceeds 25 kt limit” |
mission_service:geofence_proximity:<mission_id> | geofence_proximity | WARNING | UAV within buffer distance of geofence boundary | UAV moves away from boundary | “Mission m-42: UAV within 50m of geofence boundary” |
How alerts flow through the existing architecture:
Alerts reuse the same infrastructure as notifications with minimal additions:
- Ingestion: Producer calls
RaiseAlertorClearAlertvia gRPC — same producer integration pattern asCreateNotification. - Persistence: Alert state is stored in the
ALERTtable (see Data Model below). Thealert_keyhas a unique constraint for active alerts. - Fan-out: Alert state changes (raise, update, clear) trigger
pg_notify('alert_changes', alert_id)— the same PostgreSQL LISTEN/NOTIFY mechanism used for notification fan-out. All instances receive the event and evaluate against localStreamAlertssubscription filters. - UI delivery: Connected UI clients receive alert state changes via
StreamAlertswith the same metadata-based subscription filtering used forStreamNotifications. The UI maintains an active alert panel separate from the notification inbox. - Channel routing: Alert routing follows the same Preference Service rules — users can configure which alert types trigger email or Slack delivery. Typically, only CRITICAL severity alerts are forwarded to non-UI channels; WARNING alerts are UI-only.
- Metadata: Alerts carry the same structured metadata fields (
uav_id,mission_id,site_id, etc.) as notifications, enabling the same subscription filtering and enrichment logic.
Notification preferences (Preference Service):
The Preference Service is an internal component of the notification service that manages standing user and role-level configuration — persistent rules about which notification types a user wants and through which delivery channels. It is distinct from subscription filtering:
| Concern | Preference Service | Subscription Filter (StreamNotifications) |
|---|---|---|
| Scope | Standing configuration — applies globally to all notifications for a user | Dynamic, per-connection — applies only to the current streaming session |
| Persistence | Stored in USER_PREFERENCE table; survives disconnects and restarts | Ephemeral — exists only while the gRPC stream is open |
| What it controls | Which notification types a user receives and via which channels | Which notifications are delivered to a specific UI stream based on operational context |
| Example | “Always send CRITICAL airspace conflicts to me via email + UI; send INFO status updates to UI only” | “Right now, show me only notifications for mission m-42” |
| When it changes | User edits preferences in settings UI (UpdatePreferences gRPC call) | Operator switches context (e.g., navigates from one mission to another) |
How they work together in the routing pipeline:
- A notification arrives via
CreateNotificationand is persisted. - The Routing Engine consults the Preference Service to determine: (a) which users should receive this notification based on
event_typeand severity preferences, and (b) which channels (UI, email, Slack) are enabled for each user for this notification type. - For UI delivery, the Filter Matcher then evaluates the notification’s metadata against all active
StreamNotificationssubscription filters to determine which connected UI streams should receive it. - For non-UI channels (email, Slack), the Preference Service result is sufficient — the channel adapter delivers directly without subscription filtering.
This separation ensures that:
- An operator who has disabled email for routine status updates will never receive those via email, regardless of subscription filters.
- An operator monitoring mission m-42 in the UI will not see notifications for mission m-99 in their stream, even though their preferences allow that notification type.
- A manager who is not currently connected to the UI still receives email notifications for critical events based on their preferences.
The Preference Service stores its data in the USER_PREFERENCE table:
| Field | Purpose |
|---|---|
user_id | The user this preference applies to |
event_type | The notification event type (e.g., airspace_conflict, mission_failure, uav_anomaly, status_update) — or * for all types |
channel | The delivery channel (ui, email, slack) |
enabled | Whether delivery via this channel is active for this event type |
config | Channel-specific configuration (JSONB) — e.g., email address override, Slack channel ID, quiet hours |
Horizontal scaling and multi-instance delivery:
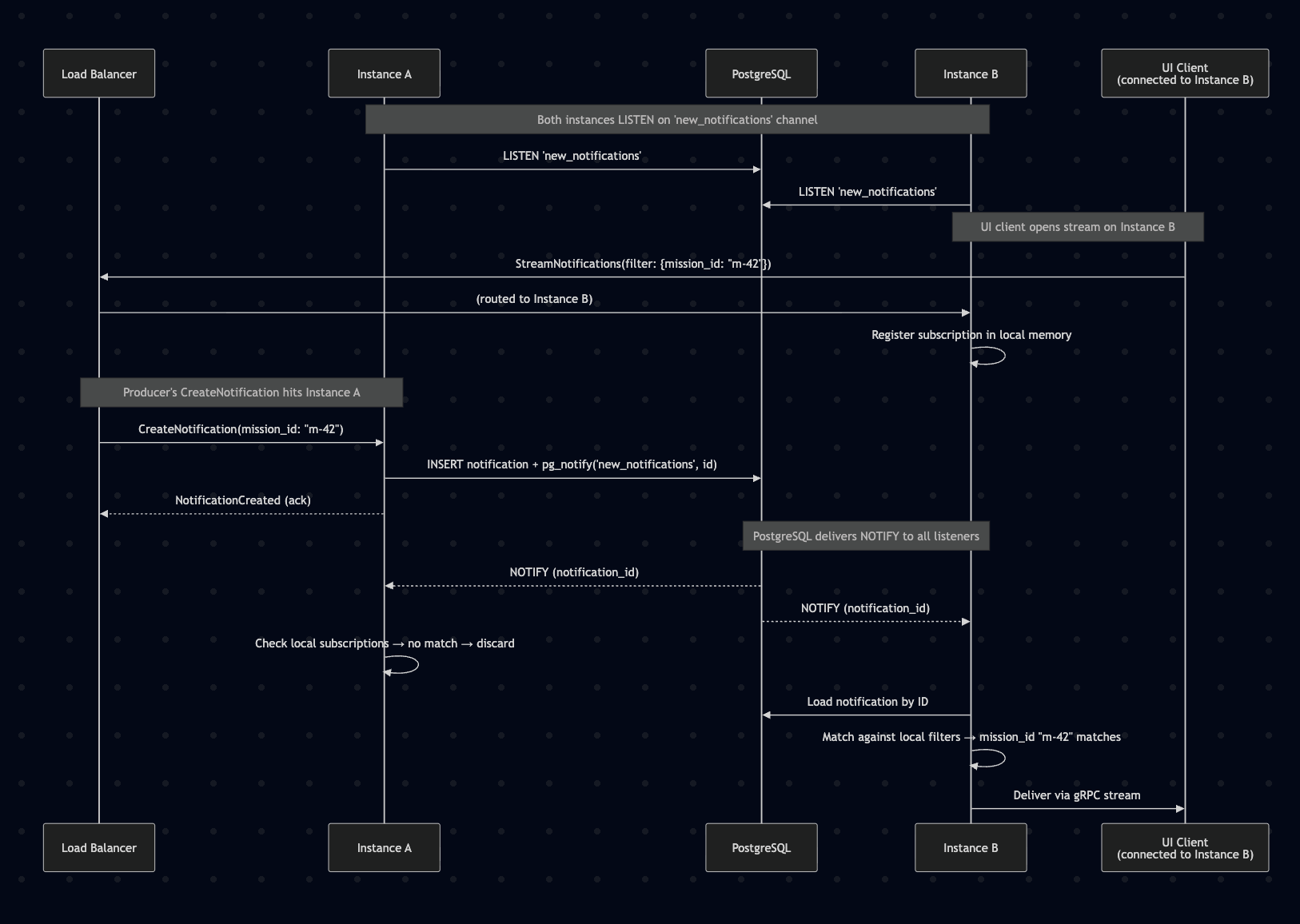
The notification service must support multiple replicas behind a load balancer for availability and throughput. This introduces a fan-out problem: a CreateNotification call may land on Instance A, but the UI client whose subscription filter matches is streaming from Instance B. Instance A cannot deliver the notification to Instance B’s connected clients without a cross-instance signaling mechanism.
The problem:
- Each instance maintains an in-memory registry of active
StreamNotificationssubscriptions (client connection + filter). CreateNotificationis load-balanced across instances — the receiving instance has no knowledge of subscriptions held by other instances.- Without cross-instance fan-out, notifications would only reach clients connected to the same instance that processed the
CreateNotificationcall.
Solution: PostgreSQL LISTEN/NOTIFY for cross-instance fan-out
PostgreSQL is already in the stack and provides a lightweight pub/sub mechanism via LISTEN/NOTIFY. This enables cross-instance notification delivery without adding new infrastructure:
- All instances open a persistent connection to PostgreSQL and
LISTENon anew_notificationschannel. - When Instance A receives a
CreateNotificationcall, it persists the notification to PostgreSQL, returns the ack to the producer, then executespg_notify('new_notifications', notification_id). - All instances (including A) receive the
NOTIFYpayload containing the notification ID. - Each instance loads the notification from PostgreSQL (or uses a short-lived local cache if A already has it), evaluates it against its local in-memory subscription filters, and delivers to matching connected streams.
- Instances with no matching subscriptions discard the event after the filter check — minimal overhead.
This approach has several advantages:
- No new infrastructure — PostgreSQL LISTEN/NOTIFY is built-in and already available.
- Low latency —
NOTIFYis delivered to listeners within the same transaction commit, typically sub-millisecond within the cluster. - Stateless load balancing —
CreateNotificationcan hit any instance;StreamNotificationscan be on any instance. No sticky sessions, no routing affinity. - Simple failure model — if an instance crashes, its subscriptions are gone (clients reconnect to another instance); other instances are unaffected.
Non-streaming operations (ListNotifications, AcknowledgeNotification, UpdatePreferences) are purely database-backed and work identically across all instances with no fan-out needed.
Why not alternatives:
| Alternative | Why not |
|---|---|
| Redis Pub/Sub | Adds a new infrastructure dependency; PostgreSQL LISTEN/NOTIFY achieves the same result with what’s already deployed |
| Sticky session routing (by user or mission) | Brittle; doesn’t work when clients subscribe to multiple filter dimensions; complicates load balancer configuration; uneven load distribution |
| Database polling | Too much latency for real-time delivery (polling interval becomes the floor); wasteful at low notification volume |
| gRPC inter-instance streaming | Complex mesh topology; O(n²) connections between instances; operationally fragile |
Scaling limits of PostgreSQL LISTEN/NOTIFY:
PostgreSQL NOTIFY is lightweight but has practical limits. The payload is limited to 8KB (we only send the notification UUID — 36 bytes). The throughput ceiling is approximately 10K–50K notifications/second depending on PostgreSQL configuration, which is well above the expected volume (< 100K notifications/day). If the platform scales beyond this, the fan-out layer can be migrated to Redis Pub/Sub or NATS without changing the producer or consumer API — only the internal fan-out mechanism changes.
Phased delivery approach:
- Phase 1: Core service with gRPC API (
CreateNotification,ListNotifications,StreamNotificationswith filtering), PostgreSQL persistence, WebGRPC endpoint for web UI notifications (in-app notification center) - Phase 2: Email delivery adapter (SMTP/SendGrid integration), metadata enrichment for cross-service field resolution
- Phase 3: Slack adapter, user notification preferences
- Phase 4: Advanced features — notification batching/digests, escalation rules, quiet hours
Diagrams
Component Architecture
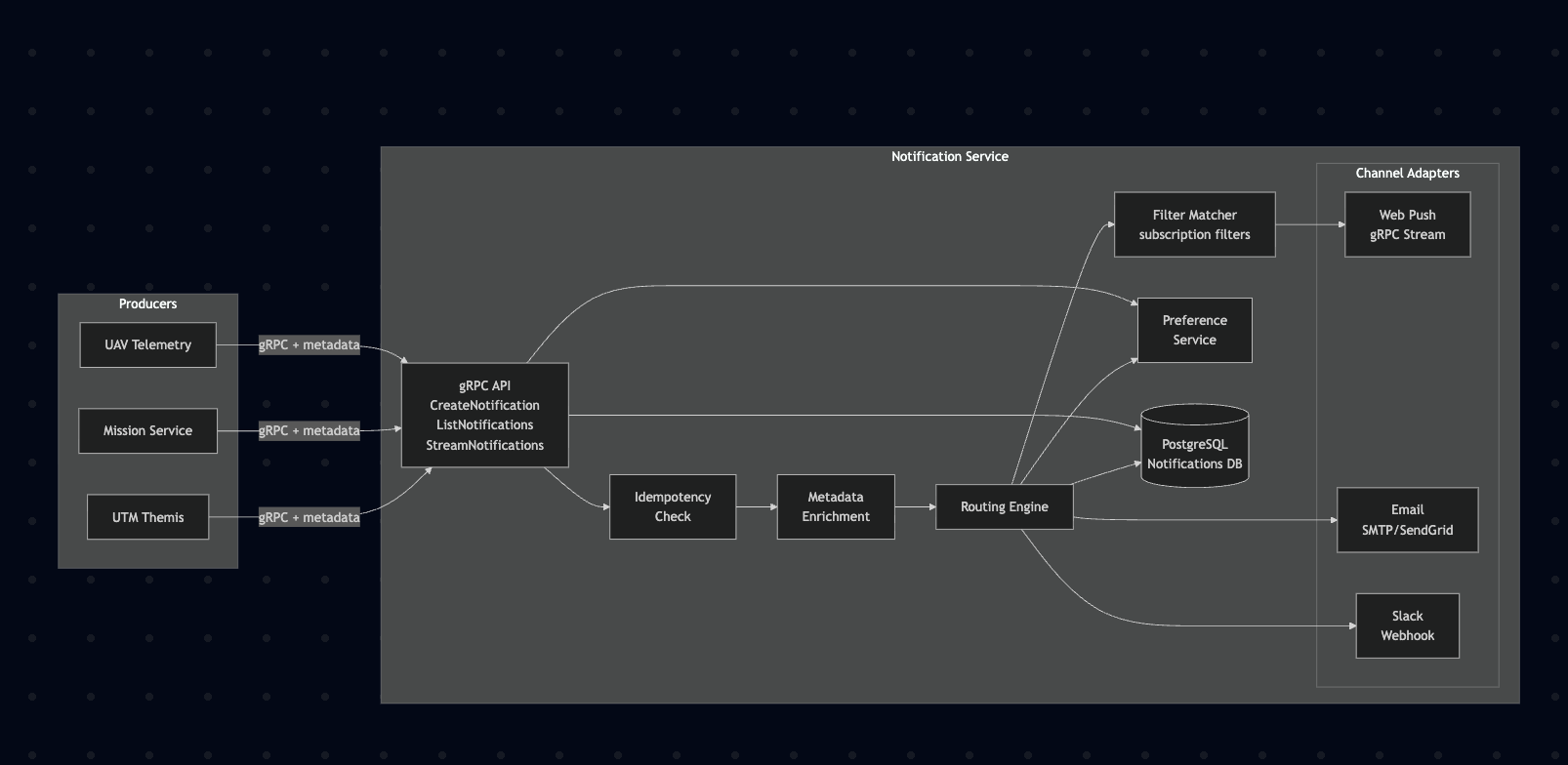
Mermaid diagram
graph LR
subgraph Producers
UTM[UTM Themis]
MS[Mission Service]
UAV[UAV Telemetry]
end
subgraph "Notification Service"
direction TB
API[gRPC API<br/>CreateNotification<br/>ListNotifications<br/>StreamNotifications]
IDEM[Idempotency<br/>Check]
ENR[Metadata<br/>Enrichment]
ROUTE[Routing Engine]
FILT[Filter Matcher<br/>subscription filters]
PREF[Preference<br/>Service]
STORE[(PostgreSQL<br/>Notifications DB)]
subgraph "Channel Adapters"
direction LR
PUSH[Web Push<br/>gRPC Stream]
EMAIL[Email<br/>SMTP/SendGrid]
SLACK[Slack<br/>Webhook]
end
end
UTM -->|gRPC + metadata| API
MS -->|gRPC + metadata| API
UAV -->|gRPC + metadata| API
API --> IDEM --> ENR --> ROUTE
ROUTE --> PREF
ROUTE --> STORE
ROUTE --> FILT --> PUSH
ROUTE --> EMAIL
ROUTE --> SLACK
API --> STORE
API --> PREF
Notification Data Model
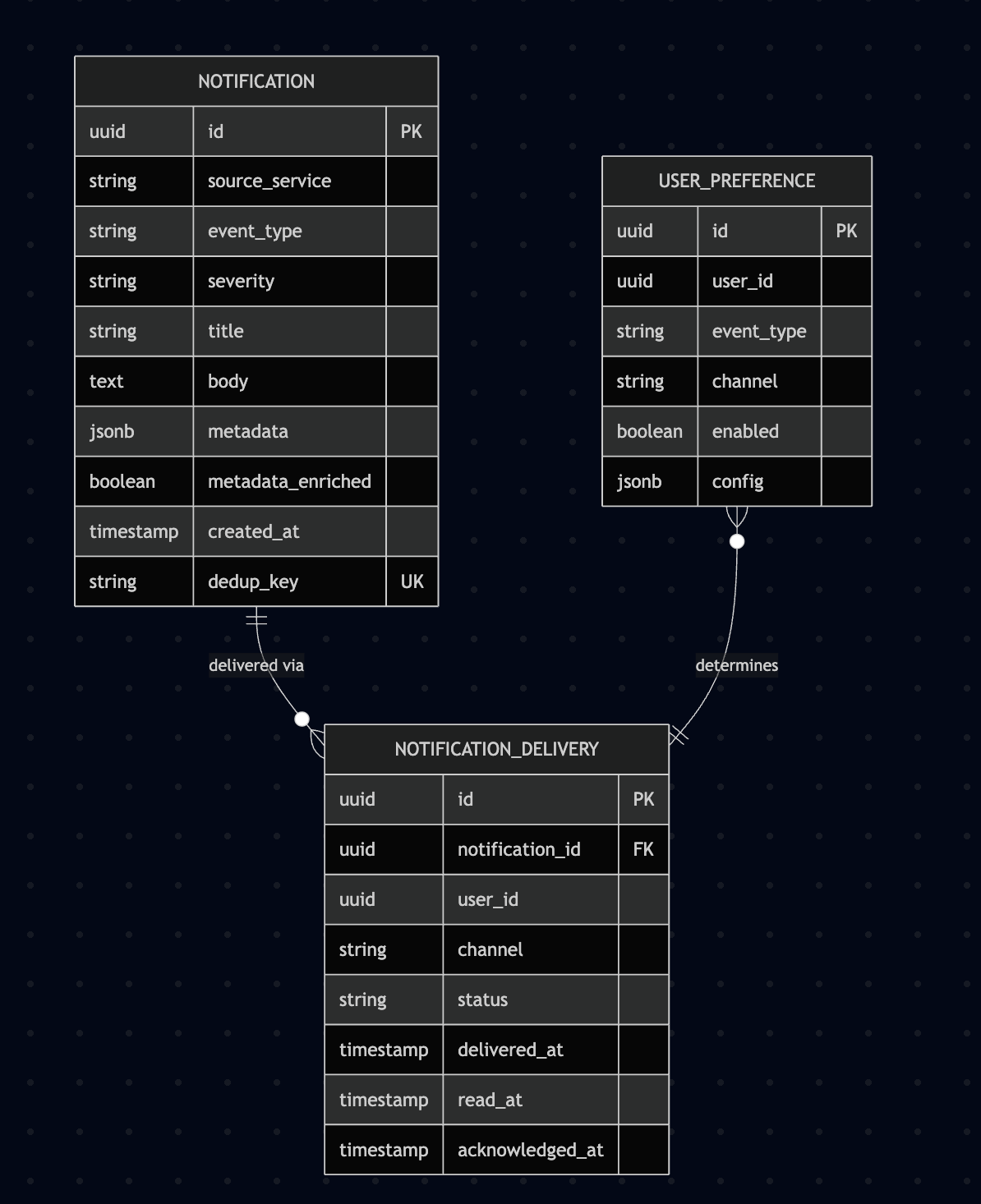
Mermaid diagram
erDiagram
NOTIFICATION {
uuid id PK
string source_service
string event_type
string severity
string title
text body
jsonb metadata
boolean metadata_enriched
timestamp created_at
string dedup_key UK
}
NOTIFICATION_DELIVERY {
uuid id PK
uuid notification_id FK
uuid user_id
string channel
string status
timestamp delivered_at
timestamp read_at
timestamp acknowledged_at
}
USER_PREFERENCE {
uuid id PK
uuid user_id
string event_type
string channel
boolean enabled
jsonb config
}
NOTIFICATION ||--o{ NOTIFICATION_DELIVERY : "delivered via"
USER_PREFERENCE }o--|| NOTIFICATION_DELIVERY : "determines"
Filter metadata fields (mission_id, site_id, uav_id, etc.) are stored as top-level indexed columns rather than buried in the jsonb metadata blob. This enables efficient subscription matching and query filtering. The metadata JSONB field retains additional unstructured context (e.g., error messages, coordinates) that doesn’t need indexing. The metadata_enriched flag indicates whether the enrichment step has resolved missing fields.
Sequence: Notification Flow from Event to UI
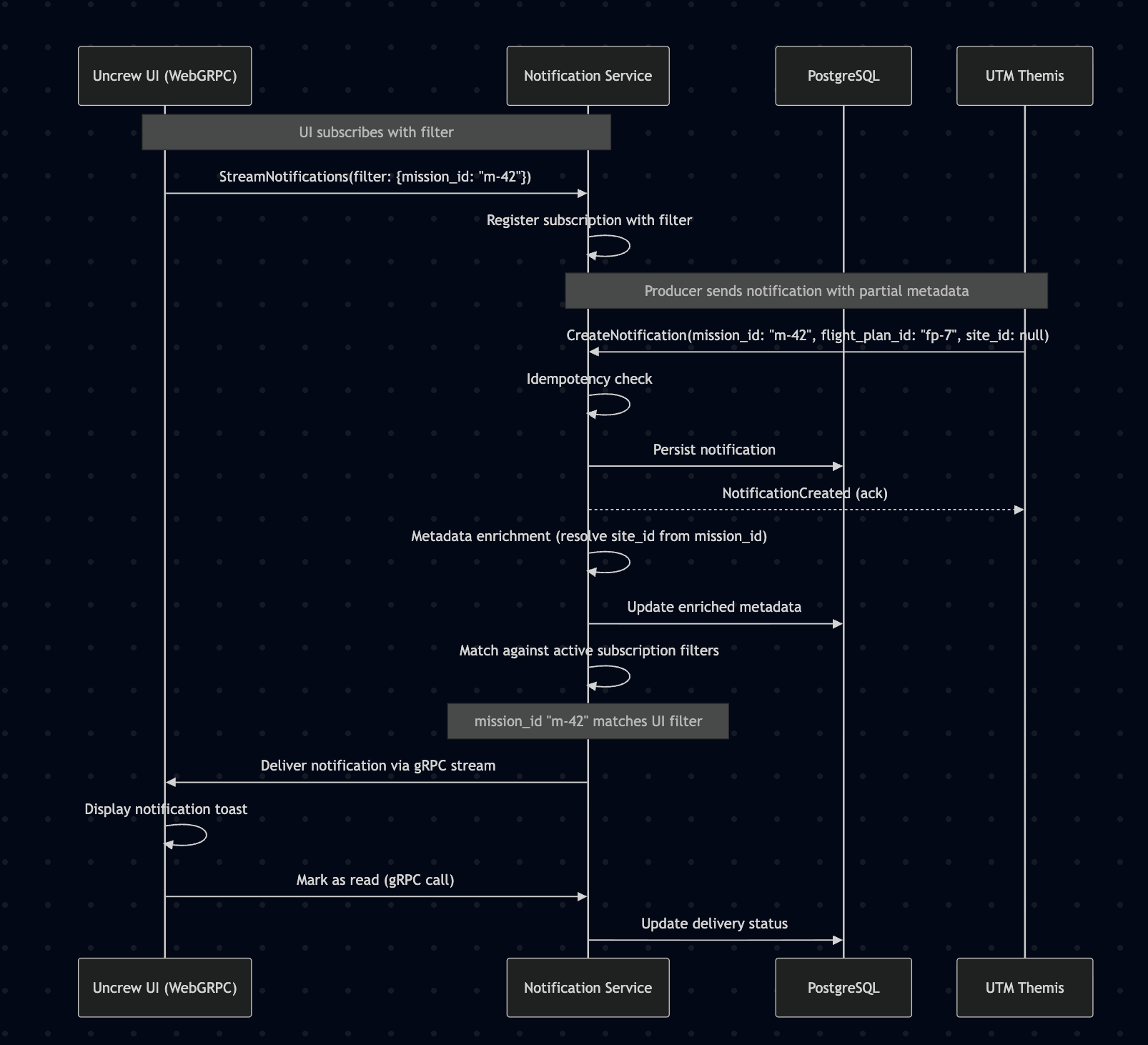
Mermaid diagram
sequenceDiagram
participant UI as Uncrew UI (WebGRPC)
participant NS as Notification Service
participant DB as PostgreSQL
participant UTM as UTM Themis
Note over UI,NS: UI subscribes with filter
UI->>NS: StreamNotifications(filter: {mission_id: "m-42"})
NS->>NS: Register subscription with filter
Note over UTM,NS: Producer sends notification with partial metadata
UTM->>NS: CreateNotification(mission_id: "m-42", flight_plan_id: "fp-7", site_id: null)
NS->>NS: Idempotency check
NS->>DB: Persist notification
NS-->>UTM: NotificationCreated (ack)
NS->>NS: Metadata enrichment (resolve site_id from mission_id)
NS->>DB: Update enriched metadata
NS->>NS: Match against active subscription filters
Note over NS: mission_id "m-42" matches UI filter
NS->>UI: Deliver notification via gRPC stream
UI->>UI: Display notification toast
UI->>NS: Mark as read (gRPC call)
NS->>DB: Update delivery status
Sequence: Subscription Filtering with Partial Metadata
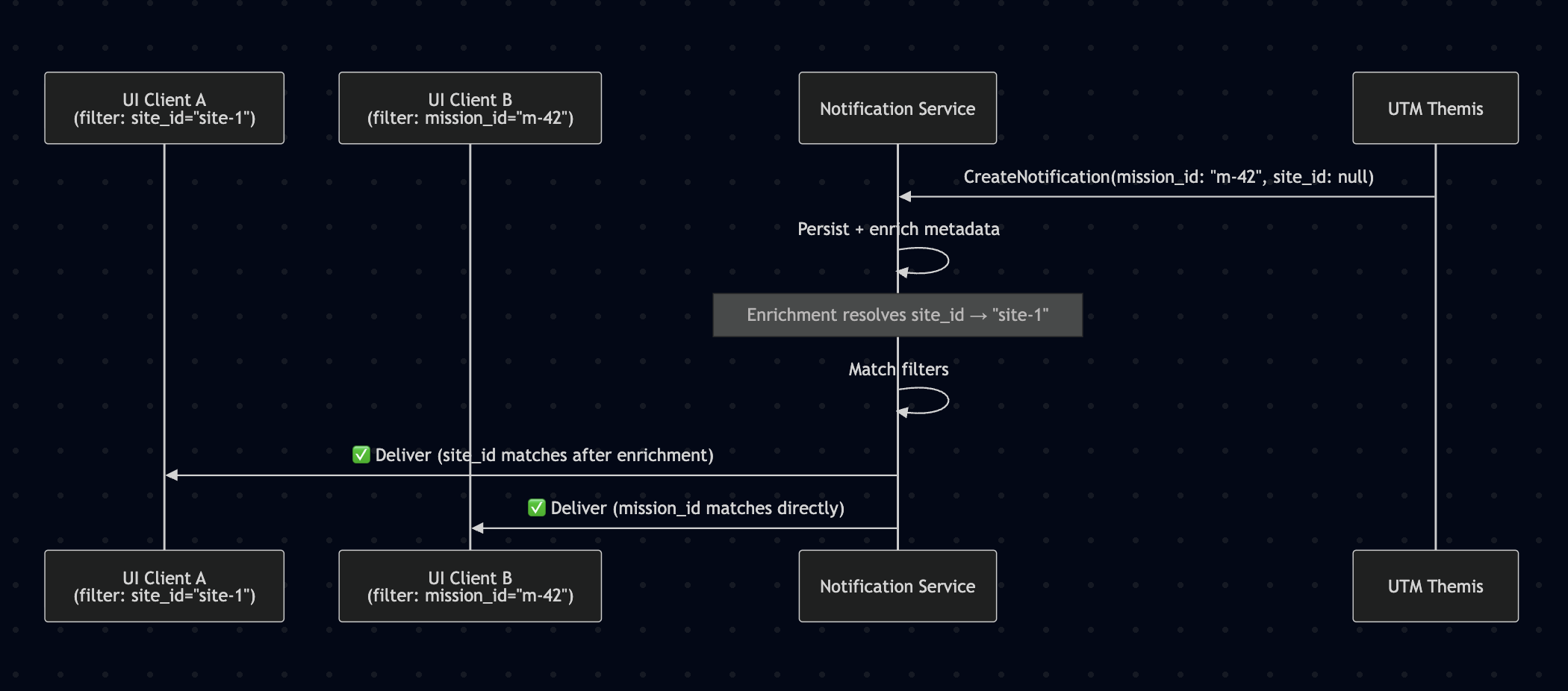
Mermaid diagram
sequenceDiagram
participant UI1 as UI Client A<br/>(filter: site_id="site-1")
participant UI2 as UI Client B<br/>(filter: mission_id="m-42")
participant NS as Notification Service
participant UTM as UTM Themis
UTM->>NS: CreateNotification(mission_id: "m-42", site_id: null)
NS->>NS: Persist + enrich metadata
Note over NS: Enrichment resolves site_id → "site-1"
NS->>NS: Match filters
NS->>UI1: ✅ Deliver (site_id matches after enrichment)
NS->>UI2: ✅ Deliver (mission_id matches directly)
Multi-Instance Fan-Out via PostgreSQL LISTEN/NOTIFY
Mermaid diagram
sequenceDiagram
participant LB as Load Balancer
participant A as Instance A
participant DB as PostgreSQL
participant B as Instance B
participant UI as UI Client<br/>(connected to Instance B)
Note over A,B: Both instances LISTEN on 'new_notifications' channel
A->>DB: LISTEN 'new_notifications'
B->>DB: LISTEN 'new_notifications'
Note over UI,B: UI client opens stream on Instance B
UI->>LB: StreamNotifications(filter: {mission_id: "m-42"})
LB->>B: (routed to Instance B)
B->>B: Register subscription in local memory
Note over LB,A: Producer's CreateNotification hits Instance A
LB->>A: CreateNotification(mission_id: "m-42")
A->>DB: INSERT notification + pg_notify('new_notifications', id)
A-->>LB: NotificationCreated (ack)
Note over DB,B: PostgreSQL delivers NOTIFY to all listeners
DB-->>A: NOTIFY (notification_id)
DB-->>B: NOTIFY (notification_id)
A->>A: Check local subscriptions → no match → discard
B->>DB: Load notification by ID
B->>B: Match against local filters → mission_id "m-42" matches
B->>UI: Deliver via gRPC stream
Safety Impact
The notification service has a direct impact on safety because it is the primary mechanism for delivering time-critical alerts — airspace conflicts, geofence breaches, mission failures, and UAV anomalies — to operators who must act on them to maintain safe flight operations. A delayed or lost notification can mean an operator is unaware of a developing hazard.
Safety-relevant aspects:
- Operator situational awareness depends on this service. Airspace conflict alerts from UTM, mission abort notifications from Mission Service, and UAV anomaly warnings all flow through the notification service to reach operators. If the service introduces excessive latency or drops notifications, operators lose the ability to respond in time, directly impacting operational safety.
- The architecture is designed for minimum latency to mitigate this risk. The direct gRPC call from producers to the notification service eliminates intermediate hops (no message broker, no async queue in the critical path). The synchronous
CreateNotification→ persist → stream-to-UI pipeline keeps the end-to-end latency to the minimum achievable within the cluster network. gRPC server-side streaming to connected UI clients delivers notifications as soon as they are persisted — no polling delay. - Persistence prevents silent notification loss. Every notification is written to PostgreSQL before acknowledgment is returned to the producer and before delivery to channels. If a channel adapter fails (e.g., Slack webhook timeout), the notification remains in the database with a failed delivery status, enabling retry and alerting. No notification is silently dropped.
- Delivery status tracking enables safety monitoring. Each notification tracks delivery state per user and per channel (pending → delivered → read → acknowledged). Operations teams can monitor delivery latency percentiles, failure rates, and acknowledgment times. Alerts on degraded delivery metrics provide early warning of pipeline health issues before they impact operator awareness.
- Graceful degradation preserves core safety path. If a non-critical channel adapter fails (email, Slack), the web UI push channel continues independently. The UI delivery path (gRPC stream) is the highest-priority channel and has no dependency on external third-party services. Even if the notification service itself becomes unavailable, operators retain direct access to source systems (UTM dashboard, mission control) as a fallback.
Mitigations summary:
| Risk | Mitigation |
|---|---|
| Notification latency too high for safety alerts | Direct gRPC ingestion (no broker), synchronous persist + stream, minimum-hop architecture |
| Notification silently dropped | Write-ahead persistence to PostgreSQL; delivery status tracking with retry |
| Channel adapter failure blocks delivery | Independent channel adapters; UI push has no external dependencies |
| Service unavailability | gRPC retry + circuit breaker on producers; operators retain direct access to source systems |
| Undetected delivery degradation | Per-notification delivery status; monitoring dashboards and alerts on latency/failure metrics |
| Multi-instance: notification not delivered to client on different instance | PostgreSQL LISTEN/NOTIFY fan-out ensures all instances are notified of every new notification; each instance evaluates its local subscriptions independently |
Assessment: The notification service is safety-relevant due to its role in operator situational awareness. The architecture is specifically designed to minimize latency and maximize delivery reliability for this reason. The direct gRPC integration, write-ahead persistence, independent channel adapters, and comprehensive delivery tracking collectively ensure that safety-critical notifications reach operators with predictable, low latency. Standard service reliability practices (health checks, delivery monitoring, graceful degradation) further reinforce the safety posture.
Assumptions
- Upstream services (UTM Themis, Mission Service, UAV) can add a gRPC client dependency on the notification service without significant architectural impact.
- The notification service gRPC endpoint will be reachable from all producing services within the cluster network.
- The Uncrew web UI can integrate a WebGRPC client for real-time notification streaming (Envoy proxy or grpc-web compatible gateway is available).
- PostgreSQL is acceptable as the notification persistence store given expected notification volumes (estimated < 100K notifications/day at peak operations).
- Email delivery can use a managed SMTP service (SendGrid, SES) rather than self-hosted mail infrastructure.
- User identity and authentication are handled by existing platform IAM — the notification service receives authenticated user context.
- Producers treat notification submission as fire-and-forget with retry — a transient failure to submit a notification does not block the producer’s primary operation.
- PostgreSQL LISTEN/NOTIFY is available and not blocked by connection poolers (e.g., PgBouncer in transaction mode does not support LISTEN — a dedicated connection per instance is required for the NOTIFY listener).
- The number of notification service instances will remain small enough (< 20) that all instances can maintain a persistent LISTEN connection to PostgreSQL without exhausting the connection pool.
Constraints
Imposed by this decision:
- All services wishing to produce notifications must add a gRPC client dependency on the notification service and call the
CreateNotificationendpoint. - Producers must attach structured filter metadata (at minimum the fields they know — e.g.,
mission_id,uav_id) to every notification; omitting all metadata degrades subscription filtering for UI clients. - The notification service becomes a required deployment dependency for the Uncrew web UI notification center.
- Channel adapters must implement a common interface to ensure consistent delivery tracking and error handling.
- The notification
.protoAPI must be versioned to support backward-compatible evolution. - Producers must implement retry logic (with exponential backoff) for notification submission to handle transient unavailability.
- Each notification service instance must maintain a dedicated PostgreSQL connection for
LISTEN(bypassing connection poolers like PgBouncer if in transaction mode). - The internal fan-out mechanism (currently PostgreSQL LISTEN/NOTIFY) must be replaceable without changing the producer or consumer API contract.
Existing constraints that shaped this decision:
- Platform standardization on Go and gRPC for all service-to-service communication.
- WebGRPC (gRPC-Web) is the established pattern for browser-to-backend communication in Uncrew.
- PostgreSQL is the standard relational datastore across Uncrew services.
Implications
- Proto definitions: New
.protofiles for the notification gRPC API (CreateNotification,ListNotifications,StreamNotificationswithSubscriptionFilter,AcknowledgeNotification,UpdatePreferences) — shared as a versioned proto package consumed by all producers and UI clients. - Producer integration: Each upstream service team must add a gRPC client for the notification service and instrument notification-worthy events with
CreateNotificationcalls, including all known filter metadata fields — estimated 1–2 days per service. - Filter metadata contract: Teams must agree on the canonical set of filter fields (
mission_id,site_id,uav_id,airspace_id,flight_plan_id,operator_id) and document which fields each producer is expected to provide. - Metadata enrichment mappings: Cross-service field resolution rules must be defined (e.g.,
mission_id→site_idvia Mission Service lookup) and the enrichment cache/lookup strategy must be implemented. - UI integration: Uncrew web frontend must implement a WebGRPC streaming client with subscription filter support — the UI sends a filter with
StreamNotificationsbased on the operator’s current context (active mission, selected site, etc.) and must update the filter when context changes. - Envoy/Gateway configuration: The existing gRPC gateway must be configured to proxy WebGRPC traffic for the notification service.
- Monitoring: New dashboards and alerts for notification delivery latency, channel failure rates, API error rates, and subscription filter match rates.
- Resilience patterns: Producers must implement gRPC retry policies with exponential backoff and circuit breakers to handle notification service unavailability gracefully.
- Database migration: New PostgreSQL schema for notifications (with indexed filter columns), deliveries, and user preferences.
- Multi-instance fan-out: Each instance needs a dedicated PostgreSQL connection for
LISTENoutside the normal connection pool. If PgBouncer is in use in transaction mode, the LISTEN connection must bypass it (direct connection to PostgreSQL). Deployment manifests must configure readiness/liveness probes to account for the LISTEN connection health. - Horizontal scaling validation: Load testing must verify that cross-instance notification delivery latency via PostgreSQL NOTIFY remains within acceptable bounds (target: < 50ms additional latency over single-instance delivery) under peak notification volume.