IoT gRPC Tunnel
Originally
ADR--0142-IoT gRPC Tunnel (v15) · Source on Confluence ↗Metadata
| Field | Value |
|---|---|
| Status | Proposed |
| Jama Requirements | UERQ-SYS-2165 |
| Proposer | Remek Zajac (Engineering) |
| Reviewers | Engineering, Product, Security |
| DAL | DAL-D Enhanced |
| Supersedes | ADR-0091-Apollo-Reversed-GRPC |
| Superseded by | N/A |
Context and Problem Statement
Onboard processes running on uncrewed aircraft and other IoT things (e.g., failureinjection, winch, mavlink-shim, geodata) provide gRPC services and consume cloud APIs. These processes run behind NAT — they have no public IP and cannot receive unsolicited inbound connections. The cloud platform therefore cannot dial them directly, which is the standard model for gRPC servers.
The failure-injection service was the immediate trigger: ground operators need to invoke FailureInjection.Inject on a live aircraft through the cloud platform. Without a traversal mechanism, there is no network path. Solving this one-off with a device-specific workaround would produce a proliferation of incompatible NAT bypass schemes as the onboard service surface grows.
A second requirement compounds the problem: mavlink-shim is a consumer rather than a server — it calls the cloud Avatar service to report state. The same traversal infrastructure must support this reversed direction without a separate tunnel implementation.
If no decision is made, onboard service exposure requires in-field port forwarding or VPN provisioning per device, which is operationally untenable at scale.
Decision Drivers
- Outbound-only connectivity from things — the solution must work when the device can dial out but cannot accept inbound connections.
- Schema independence at the cloud boundary — onboard services evolve faster than the cloud; the proxy must not require cloud redeployment when device services change.
- Protocol fidelity for gRPC streams — onboard services use bidirectional and server-streaming RPCs; the transport must carry these without semantic loss.
- Bidirectional role support — the solution must support processes running on THINGS acting either as gRPC servers (exposed by the cloud to clients) or gRPC clients (calling cloud services) or both at the same time.
- Mutual authentication without managing public PKI — things are pre-provisioned with device certificates; the tunnel authentication must use this existing mTLS infrastructure.
Considered Options
Option 1: Reverse gRPC Roles (what Mavlink-Shim does today)
Description: Mavlink-shim hit this problem first and decided to solve it by role-swapping. Mavlink-shim became a gRPC client and Avatar became a gRPC server - all despite the roles are conceptually reversed.
Pros:
- Builds on standard gRPC streaming without introducing a separate session-layer library.
Cons:
- Results in cryptic interfaces where onboard services subscribe to requests and send off band responses that they need to label with request ids. Protoc linters make matters worse forcing to label requests with “response” suffices and responses with “request” suffices.
- Forces Avatars into do relatively complex relaying between the interface they expose to the pilots and the (role-swapped) interface they expose to the onboard services.
- The solution does not generalise to the
grpc-clientrole (mavlink-shim) without a separate implementation, since that role requires the device to initiate calls, not just respond to them.
Estimated effort: ~2 sprints
Option 2: IoT gRPC Tunnel (yamux over mTLS)
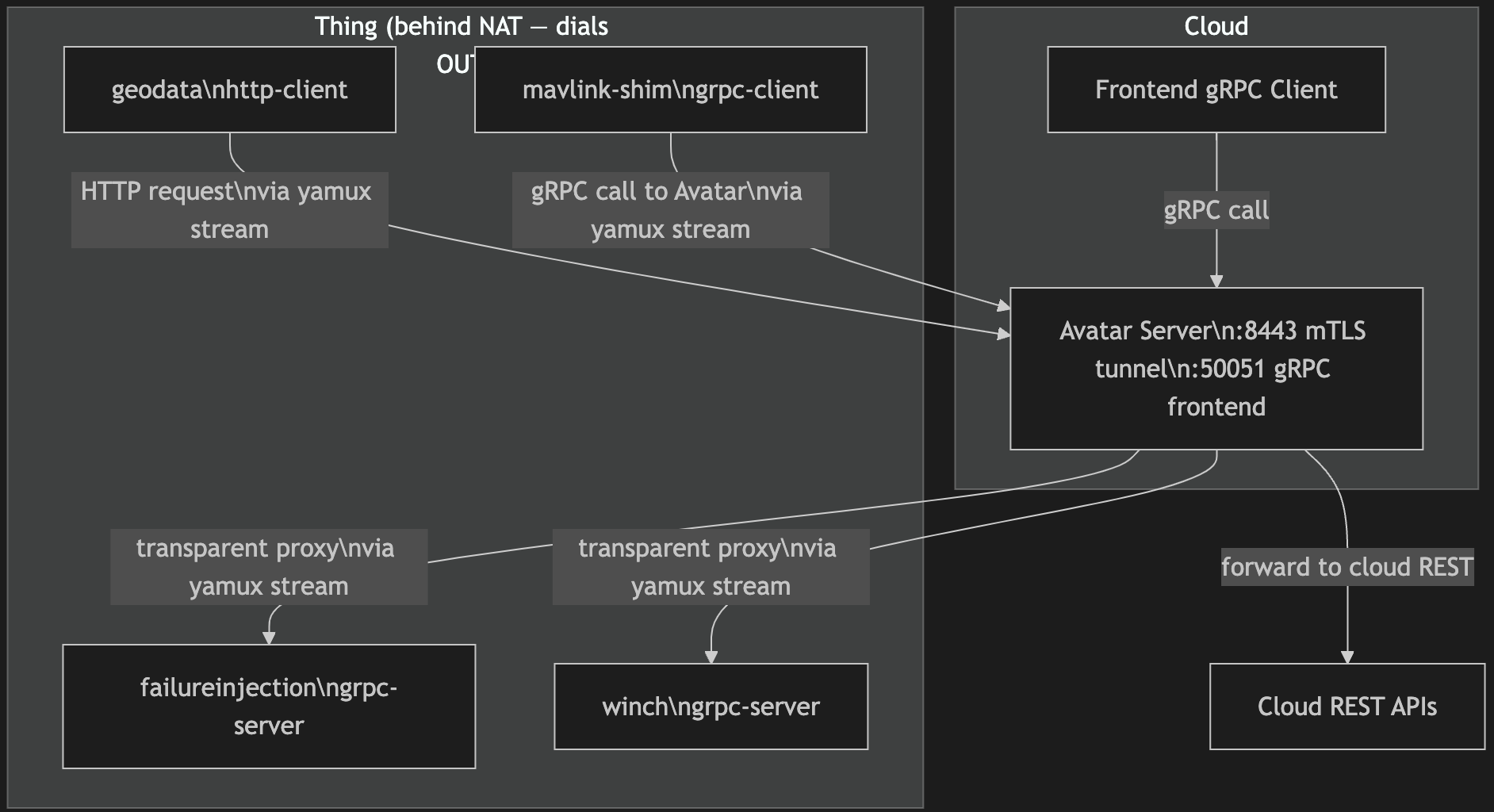
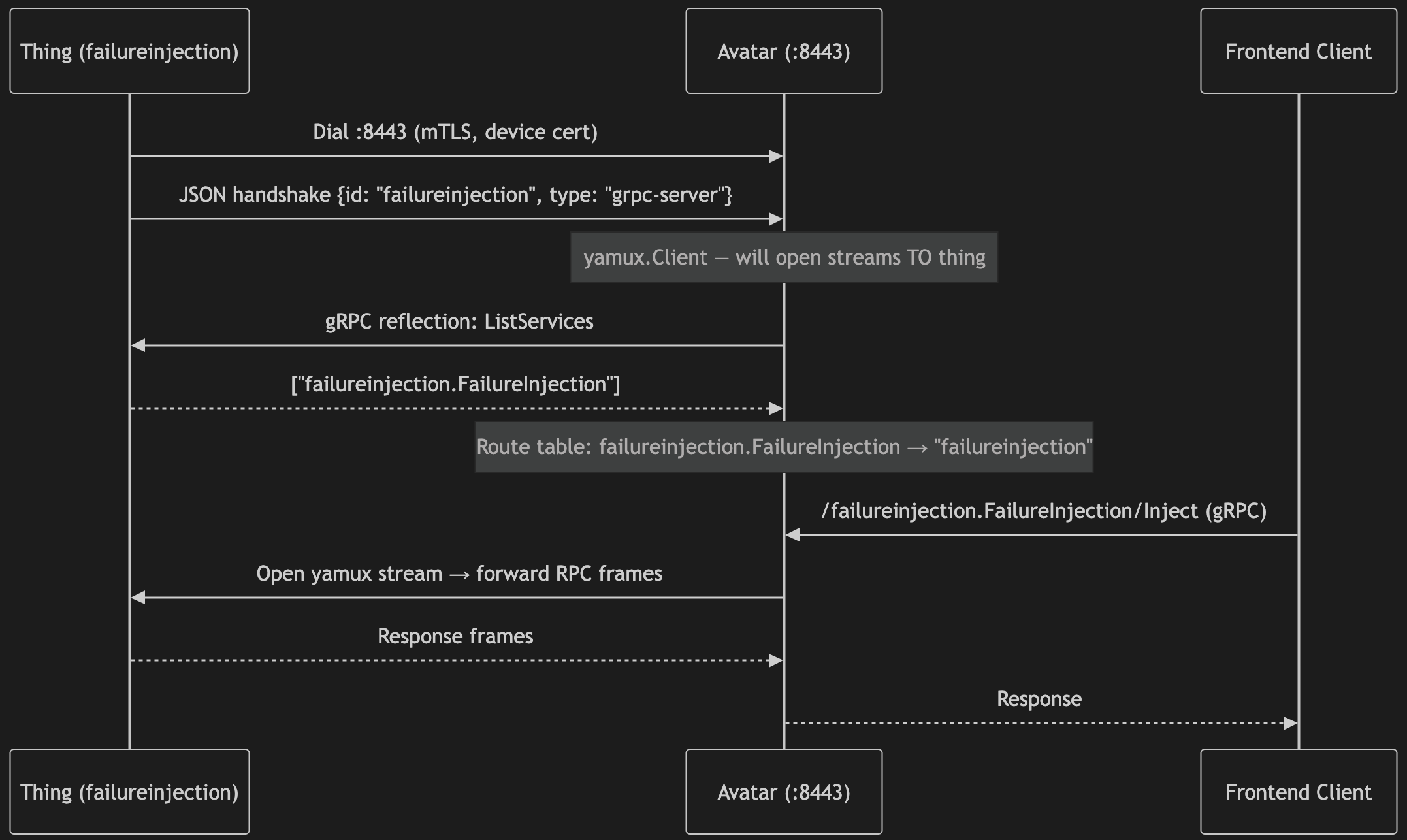
Description: Each onboard process dials the cloud avatar server on :8443 over mTLS. After a JSON handshake that identifies the client ID (just for logging) and role (grpc-server, grpc-client, or http-client), a yamux session multiplexes many logical streams over the single TLS connection. For grpc-server things, the cloud opens yamux streams inward to reach the service; for grpc-client things, the device opens streams outward to reach cloud services. The cloud uses gRPC server reflection to discover which services a newly connected thing provides, populating a routing table that drives a transparent byte-level proxy — no generated stubs or proto knowledge required in the cloud.
Pros:
- NAT is traversed by design: the thing always dials out.
- Schema independence: the transparent proxy forwards opaque proto frames; adding a new onboard service requires no cloud change.
- Full gRPC semantics preserved end-to-end, including bidirectional streaming.
- Single mTLS connection per thing multiplexes all services via yamux, keeping connection count proportional to thing count rather than service count.
- One pattern covers both directions (thing-as-server and thing-as-client).
Cons:
- Custom infrastructure: the yamux framing and reflection-based routing are not standard cloud-load-balancer features; they require maintenance.
- The cloud holds open N long-lived TLS connections (one per connected thing); connection tracking overhead scales with fleet size.
- gRPC reflection must be enabled on all onboard services; services that disable reflection fall out of the routing table silently.
Estimated effort: Prototype complete; production hardening ~1 sprint.
Option 3: VPN Overlay (WireGuard / Tailscale)
Description: Each device joins a mesh VPN. The cloud reaches device services at their VPN-assigned IPs using standard gRPC without any proxy layer.
Pros:
- No application-layer code; uses commodity infrastructure.
- Full IP connectivity — any future protocol is supported without changes.
Cons:
- Requires a VPN agent on every device and a coordination service (Tailscale orchestrator or a self-managed WireGuard key server); significant ops surface for a fleet of embedded devices.
- At the application layer, the cloud sees a VPN-assigned IP, not a device identity. Correlating a request to a specific physical device requires a separate IP-to-device registry; mTLS certificates carry structured identity (CN/SAN) that flows into application logs and audit trails directly.
- WireGuard is a Linux kernel module (kernel ≥ 5.6) or a userspace implementation; Tailscale depends on a Go runtime. Embedded platforms running RTOS, stripped-down Linux kernels, or locked-down firmware images may not support either. The IoT tunnel client requires only a TLS stack and a TCP socket — both universally available.
- WireGuard has no dynamic revocation mechanism: removing a compromised device requires editing peer configs and reloading on every node that lists it. Tailscale delegates this to its coordination server, but that is the same service already cited as an ops liability. The IoT tunnel’s mTLS approach revokes a device by adding its certificate to a CRL — no other device or config is touched.
- DroneUp prior experience suggests that VPNs can lead to fragile/degraded C2 and that reconnections take more than when using alternative solutions.
Estimated effort: ~2 sprints for infra + per-service stub regeneration on every onboard service addition.
Decision Outcome
Chosen option: “IoT gRPC Tunnel (yamux over mTLS)”
The tunnel is adopted as the standard mechanism for all onboard-to-cloud connectivity. failureinjection and winch connect as grpc-server clients, making their services available to frontend users via the transparent proxy. mavlink-shim connects as a grpc-client, calling the cloud Avatar service through the same tunnel. As mavlink-shim’s own service surface matures, it will register an additional grpc-server connection to expose those RPCs to frontend users without any cloud infrastructure change.
Reversibility: Costly to reverse. Onboard clients would need to replace the tunnel dial-out with an alternative traversal mechanism; the cloud proxy would be replaced by direct gRPC routing. Reversing is feasible but requires coordinated deployment of all onboard processes.
Argument
The core asymmetry driving this decision is that Options 1, and 3 all require the cloud to carry schema knowledge about onboard services, while Option 2 does not. gRPC reflection shifts that coupling: the cloud learns what services a thing provides at connect time, and the transparent proxy forwards frames without deserialising them. The consequence is that onboard teams can add, rename, or version services independently of cloud release schedules — a significant velocity advantage given that the onboard service surface is actively evolving.
The choice between Option 2 and Option 3 is the most consequential. A VPN overlay offers broader flexibility (any protocol, no proxy code), but at the cost of per-device agent management and permanent schema coupling. For a fleet of embedded devices where firmware updates are constrained, the operational risk of maintaining WireGuard key rotation and a Tailscale orchestrator outweighs the benefit of full IP transparency. Option 2 delivers the same routing outcome with a smaller operational footprint: a single mTLS listening port, a CA-signed device certificate already provisioned at manufacture, and no coordination service.
The bidirectional role support (driver 4) would require two separate VPN- or MQTT-based implementations — one for things that are servers, one for things that are clients. The yamux model collapses both into one: the cloud acts as yamux.Client toward grpc-server things (opening streams inward) and as yamux.Server toward grpc-client things (accepting streams from the device). This duality is why mavlink-shim’s evolution path — today a caller of Avatar, tomorrow also a provider of its own RPCs — requires no new infrastructure: it simply registers a second tunnel connection with type grpc-server.
The main trade-off accepted is that gRPC reflection is now a mandatory deployment requirement for all onboard grpc-server processes. Services that disable reflection vanish from the routing table without error, which is operationally invisible. This risk is mitigated by making reflection enablement a checklist item in the onboard service deployment runbook and by adding a health-check that validates the routing table after connect.
Transport layer
Two version of the solution exist, with and without the usage of yamux.
yamux was not chosen for stream multiplexing — in the current deployment each onboard process establishes one tunnel connection and serves one service, so concurrent stream counts are low and multiplexing is not the point.
A reasonable question is whether yamux is needed at all and the following deliberation endorses the one without yamux.
After the mTLS handshake and JSON identity exchange, both sides hold a live, authenticated net.Conn. This raw connection is used directly as the gRPC transport:
grpc-serverthings (Go): Avatar injects the conn viagrpc.WithContextDialer; gRPC-Go’s HTTP/2 client dials it immediately. The thing wraps the same conn in anOneshotListenerand callsgrpc.Server.Serve— gRPC’s HTTP/2 layer multiplexes all concurrent RPCs over the single connection. AnotifyConnwrapper detects when gRPC closes the conn and signals the reconnect loop.grpc-clientthings (Go): The thing injects the conn viagrpc.WithContextDialerto reach Avatar. Avatar’s side pushes the conn into a sharednet.Listenerthat its gRPC server drains.http-clientthings: The thing writes an HTTP/1.1 request directly on the raw conn; Avatar reads and forwards it. Single-roundtrip.
Why no yamux? After assessing each originally-stated justification:
- GOAWAY recycling — When the UAV’s gRPC
grpc.ClientConnreceives GOAWAY it re-dials. With a raw conn the dialer returns the already-open conn; the new HTTP/2 session starts immediately. If the TCP connection is dead, yamuxsession.Open()also fails — recovery requires the UAV to re-dial the mTLS tunnel either way. yamux bought nothing here that a UAV-side reconnect loop doesn’t already handle. - C++ has no
WithContextDialer— The C++ gRPC library cannot be handed a pre-existingnet.Conn. This is solved independently of yamux by byte-proxying the raw SSL connection to a local Unix socket. See the C++ section below. - Multiple cloud clients per tunnel conn — Solved by Avatar caching a single
grpc.ClientConnper attached thing and reusing it across callers. No session-layer multiplexing needed.
Removing yamux eliminates ~200 lines of session-layer protocol, one dependency, and a whole class of stream-lifecycle bugs, with no loss of functionality.
C++ implementation: the Unix socket bridge
Go’s gRPC library exposes grpc.WithContextDialer, which lets a client inject an arbitrary net.Conn as the transport — in this codebase that is simply a yamux.Session.Open() call. The C++ gRPC library has no equivalent. A C++ grpc::Server can only accept connections on a bound address (TCP or Unix socket); it cannot be handed a pre-existing file descriptor or a custom accept loop.
The consequence for the winch service (C++ grpc-server) is an additional indirection layer: YamuxGrpcBridge runs a loop that accepts yamux streams from the tunnel session and, for each one, connects to a locally-bound Unix domain socket where the gRPC server is listening. The yamux stream and the Unix socket are then byte-proxied in both directions by a pair of background threads. The gRPC server itself is unmodified; it has no knowledge of the tunnel.
This adds one local IPC hop that Go services avoid entirely. The latency cost is bounded by loopback throughput — empirical overhead is in the 10–50 µs range per call (noted in code comments) and is negligible against the WAN RTT to the aircraft. The more significant cost is the detached thread pair per stream: under heavy concurrent call load this is a thread-per-connection model, which would require a thread-pool rework if call concurrency grows beyond O(10).
No alternative was found within the standard C++ gRPC library that avoids this indirection. Custom channel credentials and grpc::experimental::ExternalConnectionAcceptor were evaluated but neither provides a stable, non-experimental path to injecting a yamux stream as a transport connection.
Diagrams
Tunnel Topology and Traffic Flows
Connection Setup Sequence (grpc-server case)
(Flight) Safety Impact
The tunnel introduces a new bidirectional network interface between the cloud and processes running on the aircraft. Three of the five safety questions warrant attention:
- Safety-critical data flows —
mavlink-shimis proximate to the MAVLink flight-control stack. The tunnel carries RPCs tomavlink-shim(Avatar calls) and will carry RPCs from it (future grpc-server registration). Any RPC that influences flight-control parameters transits this interface. Mitigation: RPCs with flight-control effect must be reviewed against the safety case; the tunnel itself is transport-only and does not interpret payload content. - Failure detection — A silent tunnel failure would make onboard services unreachable without alerting the cloud. Mitigation: yamux keepalives are enabled; the avatar server logs disconnection events and removes routes from the table meanwhile onboard components attempt to reestablish the mTLS tunnel.
Questions 4 (derived requirements) and 5 (DAL reclassification) are not triggered: the tunnel is a transport mechanism with no safety function and does not couple safety-critical and non-critical computation.
Overall: Safety impact exists and is bounded. Mitigations are identified; formal treatment is deferred to the safety case review for the onboard software stack.
Security
- Attack surface — The
:8443endpoint is exposed to the internet. mTLS with a device-specific CA limits connection to pre-provisioned things; a compromised device certificate would grant network-level access to the associated thing’s services only. Certificate rotation procedures must be defined. - Certificates installed on UAVs are not protected and an attacker could install a process that will be successful communicating with Avatar and things it proxies to. This is a broader issue and a whole new chapter that we must explore, but as a local mitigtation, Avatar should whitelist services it can proxy to. E.g.: Just geodata service.
Performance Impact
The tunnel adds two layers of overhead relative to a direct gRPC call: the yamux session layer and a single additional TCP hop through the Avatar proxy.
Per-RPC overhead: Each call traverses two gRPC stream hops (frontend → Avatar → thing) instead of one. The transparent proxy copies frames without deserialisation, so CPU cost is proportional to payload size, not schema complexity. For the control-path RPCs in scope (FailureInjection.Ingest, Winch.*), payloads are small (<1 KB) and the dominant latency is network RTT to the device, not proxy overhead.
Connection overhead: The cloud holds one long-lived yamux session per connected thing. yamux multiplexes all streams over that session; opening a new RPC stream costs a yamux header exchange (~few bytes) rather than a TLS handshake. For bursty short-lived RPCs this is a net improvement over per-call connection establishment.
Known unknowns: No load test has been run against the proxy under concurrent multi-thing traffic. The sharedListener channel buffer is sized at 64 connections; under burst conditions this could back-pressure handleTunnelConnectionGRPCClient. This should be validated before production fleet deployment.
Assumptions
- Onboard services enable gRPC server reflection; this is enforced via deployment runbook, not code.
- The fleet size and connection churn rate remain within the resource envelope of a single Avatar instance for the foreseeable future. Horizontal scaling of the tunnel server (if needed) is a separate ADR.
- The existing device certificate provisioning process produces mTLS certificates trusted by the Avatar CA; no new PKI infrastructure is required.
- yamux session-layer reliability is sufficient for the RPC latency requirements of onboard services; no independent measurement of latency overhead has been done.
Constraints
Imposed by this decision:
- All onboard
grpc-serverprocesses must enable gRPC server reflection. - The
tunnelHandshakeJSON schema (id,type) is a protocol contract between onboard processes and the cloud; changes require coordinated deployment. The handshake is non-standard and thus unfortunate. Insofar that grpc-servers must behave in a non-standard way, (wrap their end of the tunnel in a listener), it would be desirable for grpc- and http- clients to behave just like they spoke to an mTLS authenticated server and not deal with any handshakes. This is a potential improvement we still can try by using cmux. We already use cmux in the avatar to implement the http proxy for geodata service. Cmux works by peeking the first bytes of the incoming traffic and making a routing decision based on whether this looks like a grpc or http client calling. If that fails and we have to stick with the handshake, we should schema-version it. - New onboard service types must fit one of the three connection roles (
grpc-server,grpc-client,http-client); services that don’t fit require an extension to the tunnel protocol.
Pre-existing constraints that shaped this decision:
- Things are behind NAT with no inbound port forwarding available.
- Device certificates are pre-provisioned; the solution must authenticate against the existing CA.
- The cloud platform is gRPC-native; HTTP/REST-only solutions would require additional translation layers.
Implications
- Reflection enforcement — A health-check or CI gate must verify that all onboard gRPC services expose reflection before they are declared production-ready.
- Tunnel failure alerting — A monitoring ADR is needed to define how tunnel disconnects are surfaced to operations.
- Certificate rotation — The device certificate lifecycle (expiry, revocation, rotation) must be defined; the tunnel today has no mechanism for certificate rotation without a service restart.
- mavlink-shim grpc-server registration — When
mavlink-shimis ready to expose its own RPC surface, it registers a second tunnel connection of typegrpc-server. No cloud-side changes are required beyond enabling reflection in the onboard process. - Horizontal scaling — If fleet size grows beyond single-instance capacity, the routing table and
sharedListenermust be externalised. This is a future ADR.
Related Artifacts
PoC can be found here at the time of writing this ADR.
If that’s gone, attaching the zipped PoC.